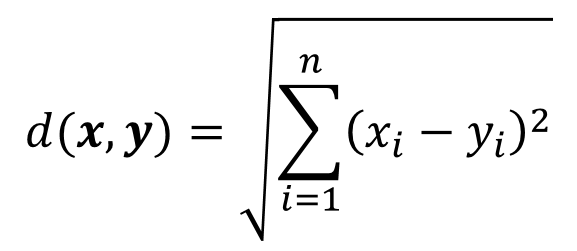最近一直在学习NLP里最基础的几个语言模型:隐马尔科夫模型(Hidden Markov Model,HMM)、最大熵马尔科夫模型(Maximum Entropy Markov Model,MEMM)和条件随机场(Conditional Random Field,CRF)。这三种模型在自然语言处理中,可以解决分词(segment,Seg)、标注(Tag)和命名实体识别(Named Entity Recognition,Ner)等问题。学习的时候参考最多的两本书是李航老师的《统计学习方法》和吴军老师的《数学之美》。如需这两本书的电子版可以给我留言。
我先分别简单介绍一下几种模型,具体的推导过程就不列出来,《统计学习方法》上有非常详细的数学原理。
HMM
下图是《统计学习方法》中的描述:

隐马尔科夫模型
HMM模型将状态序列看作马尔可夫链,一阶马尔可夫链式针对相邻状态的关系进行建模,其中每个状态对应一个概率函数。HMM是一种生成模型(Generative Model),定义了联合概率分布 ,其中
和
分别表示观测序列和状态序列的随机变量。
如果需要一些浅显简单的例子来理解HMM,下面的一个知乎问题和一篇博客可能有所帮助:
Maximum Entropy Model
首先贴一下关于最大熵模型的定义:

最大熵模型
最大熵模型的基本思想就是不要把所有鸡蛋放到一个篮子里。式(6.12)中的
是特征函数,代表各个约束条件。最大熵模型就是在符合所有约束条件下作出最不偏倚的假设,求得可使熵最大化的概率分布。熵最大,表示该系统内各随机事件(变量)发生的概率是近似均匀的,等可能性的。
最大熵模型可以使用任意的复杂相关特征(即特征函数),在性能上最大熵分类器超过了Bayes分类器。但是,作为一种分类器模型,这两种方法有一个共同的缺点:每个词都是单独进行分类的,标记状态之间的关系无法得到充分利用,具有马尔可夫链的HMM模型可以建立标记之间的马尔可夫关联性,这是最大熵模型所没有的。
最大熵模型的优点:首先,最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型;其次,最大熵统计模型可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度;再次,它还能自然地解决了统计模型中参数平滑的问题。
最大熵模型的不足:首先,最大熵统计模型中二值化特征只是记录特征的出现是否,而文本分类需要知道特征的强度,因此,它在分类方法中不是最优的;其次,由于算法收敛的速度较慢,所以导致最大熵统计模型它的计算代价较大,时空开销大;再次,数据稀疏问题比较严重。
MEMM
最大熵马尔科夫模型把HMM模型和Maximum Entropy模型的优点集合成一种生成模型(Generative Model),这个模型允许状态转移概率依赖于序列中彼此之间非独立的特征上,从而将上下文信息引入到模型的学习和识别过程中,提高了识别的精确度,召回率也大大的提高,有实验证明,这个新的模型在序列标注任务上表现的比HMM和无状态的最大熵模型要好得多。

最大熵马尔科夫模型
可以注意到MEMM在每个节点对所有可能的状态
求和然后用做局部归一化的分母。所以MEMM中节点状态转移的概率都是归一化的概率。
HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关(一阶马尔可夫模型)。但MEMM模型克服了观察值之间严格独立产生的问题,但是由于状态之间的假设理论,使得该模型仍然存在标注偏置问题(Label Bias Problem)。
关于标注偏置问题,网上最多的是下面这个例子解释:

路径1-1-1-1的概率:0.4*0.45*0.5=0.09
路径2-2-2-2的概率:0.018
路径1-2-1-2的概率:0.06
路径1-1-2-2的概率:0.066
由此可得最优路径为:1-1-1-1

而实际上,在上图中,状态1偏向于转移到状态2,而状态2总倾向于停留在状态2,这就是所谓的标注偏置问题,由于分支数不同,概率的分布不均衡,导致状态的转移存在不公平的情况。
例子的出处参见标注偏置问题(Label Bias Problem)和HMM、MEMM、CRF模型比较
CRF

线性链条件随机场模型
这是书上关于条件随机场的简化形式。本文所提的CRF都不是广义上最大熵准则建模条件概率的条件随机场模型,而是约束在线性链上的特殊的条件随机场,称为线性链条件随机场(linear chain CRF)。CRF属于判别模型(Discrimitive Model)。

线性链条件随机场模型图示
上式中也同样有
特征函数。之前我对模型中的特征函数一直不太理解。大家可以参考中文分词入门之字标注法4这篇文章。文章主要介绍借用条件随机场工具“CRF++: Yet Another CRF toolkit”来完成字标注中文分词的全过程。其中提及了特征模板文件,它的特征提取可能包含了前后多个节点的观测序列。顺便推荐一下这个非常厉害的群体博客52nlp。
《数学之美》里“徐志摩喜欢林徽因”的例子也可供参考。
CRF模型的优点:首先,CRF具有很强的推理能力,并且能够使用复杂、有重叠性和非独立的特征进行训练和推理,能够充分地利用上下文信息作为特征,还可以任意地添加其他外部特征,使得模型能够获取的信息非常丰富。其次,CRF的性能更好,CRF对特征的融合能力比较强,识别效果好于MEMM。
CRF模型的不足:使用CRF方法的过程中,特征的选择和优化是影响结果的关键因素,特征选择问题的好与坏,直接决定了系统性能的高低。而且,CRF训练模型的时间较长,且获得的模型很大,在一般的PC机上无法运行。
更多一些详细的CRF解释可以参考知乎的相关问题如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?
MEMM与CRF区别
上面的公式都是别人贴图里的,下面的公式是我走心地敲出来的,方便看出两者的差异。
MEMM的公式表示如下:
线性链CRF的公式表示如下:
不同点:
-
首先,CRF是判别模型,而MEMM我个人理解是生成模型。MEMM是在HMM基础上的优化,它保留了“状态的转移过程中当前状态只与前一状态有关”这一个独立性假设,状态与状态之间的转移仍是遵循一个不大于1的、只在同一结点作归一化的局部归一化概率,与HMM的思想相近。
-
MEMM和CRF的归一化位置不同。从上面的公式可以看出,MEMM是在given前一状态
的情况下,对下一个节点所有可能的
作局部的归一化,利用最大熵模型,从观测序列
和前一状态
中的特征学习到
的分布。而CRF是对
中所有可能的状态序列作全局的归一化,假设每个节点有
中状态,序列中有
个节点,那么所有可能的状态序列数为
,这导致在模型学习时会较为复杂。
-
MEMM在用viterbi算法求解最优路径时,每次乘上的是个归一化概率,而CRF乘上的是一个自然指数,没有经过归一化。当遇到某些不公平的情况:某条路径自然指数本身很小,但归一化后变为一个很大的概率比如0.9,而同时即使别的路径自然指数很大,但它们竞争也激烈,归一化后的概率反而不大,这样前一条路径就会被选中,导致了之前提过的标记偏置问题,而CRF可以避免这一问题。
关于MEMM和CRF两者的区别,推荐可以参考下面的一个知乎问题和一篇博客:
写在最后
关于用做封面的那张图,是对相关模型一个非常抽象、宏观的转换图,感觉非常精髓,出处为An introduction to conditional random fields。
以上均为本小白个人理解,如有任何不当或者错误,欢迎指正。
转载请注明:学时网 » HMM、MEMM和CRF的学习总结(分词算法)