本文及后续文章,Redis版本均是v3.2.8
本篇文章我们来分析下一种特殊编码的双向链表-ziplist(压缩列表),这种数据结构的功能是将一系列数据与其编码信息存储在一块连续的内存区域,这块内存物理上是连续的,逻辑上被分为多个组成部分,其目的是在一定可控的时间复杂读条件下尽可能的减少不必要的内存开销,从而达到节省内存的效果。
一、ziplist描述
先看下官方对ziplist的整体描述
/* The ziplist is a specially encoded dually linked list that is designed
* to be very memory efficient. It stores both strings and integer values,
* where integers are encoded as actual integers instead of a series of
* characters. It allows push and pop operations on either side of the list
* in O(1) time. However, because every operation requires a reallocation of
* the memory used by the ziplist, the actual complexity is related to the
* amount of memory used by the ziplist.
*
从上述的描述中,知道ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作。
一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist却是将表中每一项存放在前后连续的地址空间内。一个ziplist整体占用一大块内存,它是一个表(list),但其实不是一个链表(linked list)。
ziplist为了节省内存,提高存储效率,对于值的存储采用了变长的编码方式,大概意思是说,对于大的整数,就多用一些字节来存储,而对于小的整数,就少用一些字节来存储。
二、ziplist数据结构定义
看下官方对ziplist整体布局
* —————————————————————————-
*
* ZIPLIST OVERALL LAYOUT:
* The general layout of the ziplist is as follows:
* <zlbytes><zltail><zllen><entry><entry><zlend>
*
* <zlbytes> is an unsigned integer to hold the number of bytes that the
* ziplist occupies. This value needs to be stored to be able to resize the
* entire structure without the need to traverse it first.
*
* <zltail> is the offset to the last entry in the list. This allows a pop
* operation on the far side of the list without the need for full traversal.
*
* <zllen> is the number of entries.When this value is larger than 2**16-2,
* we need to traverse the entire list to know how many items it holds.
*
* <zlend> is a single byte special value, equal to 255, which indicates the
* end of the list.
*
从以上的布局中,我们可以看到ziplist内存数据结构,由如下5部分构成:
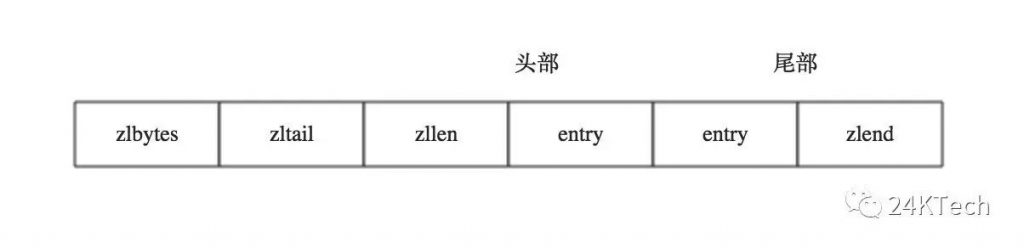
各个部分在内存上是前后相邻的并连续的,每一部分作用如下:
- zlbytes: 存储一个无符号整数,固定四个字节长度(32bit),用于存储压缩列表所占用的字节(也包括<zlbytes>本身占用的4个字节),当重新分配内存的时候使用,不需要遍历整个列表来计算内存大小。
- zltail: 存储一个无符号整数,固定四个字节长度(32bit),表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
- zllen: 压缩列表包含的节点个数,固定两个字节长度(16bit), 表示ziplist中数据项(entry)的个数。由于zllen字段只有16bit,所以可以表达的最大值为2^16-1。 注意点:如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以表示。ziplist是如何做到的?如果<zllen>小于等于2^16-2(也就是不等于2^16-1),那么<zllen>就表示ziplist中数据项的个数;否则,也就是<zllen>等于16bit全为1的情况,那么<zllen>就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。
- entry,表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构。
- zlend, ziplist最后1个字节,值固定等于255,其是一个结束标记。
* ZIPLIST ENTRIES:
* Every entry in the ziplist is prefixed by a header that contains two pieces
* of information. First, the length of the previous entry is stored to be
* able to traverse the list from back to front. Second, the encoding with an
* optional string length of the entry itself is stored.
*
* The length of the previous entry is encoded in the following way:
* If this length is smaller than 254 bytes, it will only consume a single
* byte that takes the length as value. When the length is greater than or
* equal to 254, it will consume 5 bytes. The first byte is set to 254 to
* indicate a larger value is following. The remaining 4 bytes take the
* length of the previous entry as value.
*
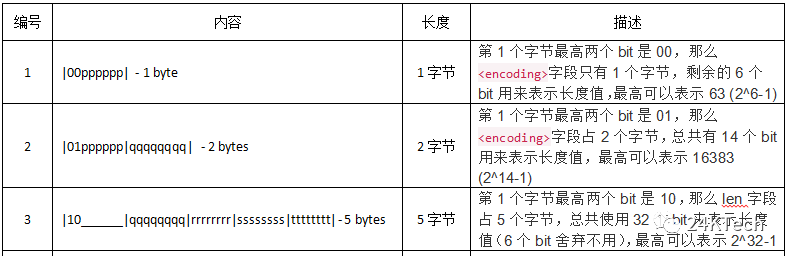
* The other header field of the entry itself depends on the contents of the
* entry. When the entry is a string, the first 2 bits of this header will hold
* the type of encoding used to store the length of the string, followed by the
* actual length of the string. When the entry is an integer the first 2 bits
* are both set to 1. The following 2 bits are used to specify what kind of
* integer will be stored after this header. An overview of the different
* types and encodings is as follows:
*
* |00pppppp| – 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* |01pppppp|qqqqqqqq| – 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* |10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| – 5 bytes
* String value with length greater than or equal to 16384 bytes.
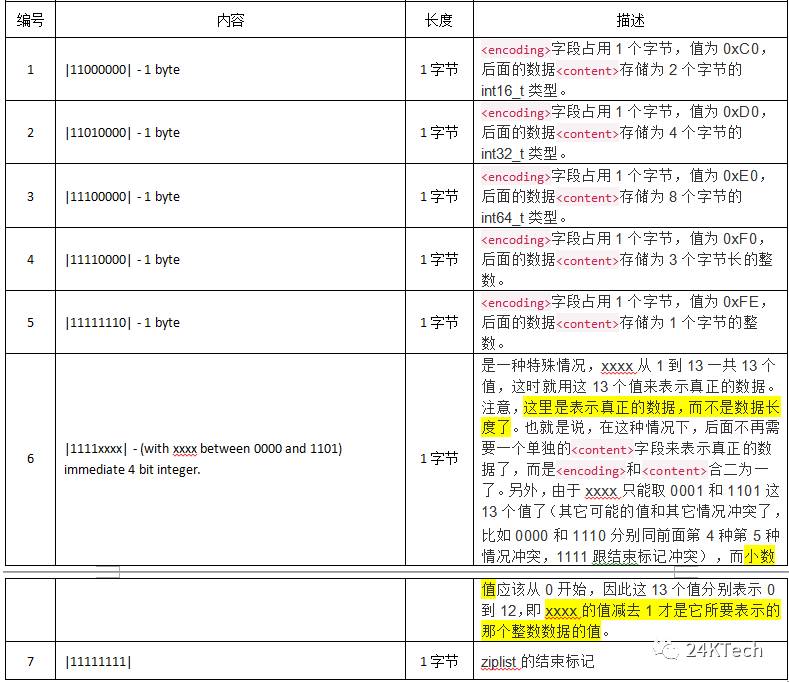
* |11000000| – 1 byte
* Integer encoded as int16_t (2 bytes).
* |11010000| – 1 byte
* Integer encoded as int32_t (4 bytes).
* |11100000| – 1 byte
* Integer encoded as int64_t (8 bytes).
* |11110000| – 1 byte
* Integer encoded as 24 bit signed (3 bytes).
* |11111110| – 1 byte
* Integer encoded as 8 bit signed (1 byte).
* |1111xxxx| – (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| – End of ziplist.
*
* All the integers are represented in little endian byte order.
*
* —————————————————————————-
每个数据项entry由三部分构成:

- previous length(pre_entry_length): 表示前一个数据节点占用的总字节数,这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移previous length个字节,就找到了前一项)。这个字段采用变长编码。
- encoding(encoding&cur_entry_length):表示当前数据节点content的内容类型以及长度。也采用变长编码。
- content:表示当前节点存储的数据,content的内容类型有整数类型和字节数组类型,且某些条件下content的长度可能为0。
pre_entry_length和encoding&cur_entry_length都是采用可变长编码,ziplist是如何实现的哪?
我们接着看第二段和第三段的官方解释:
1、pre_entry_length,节点的长度占用的字节数根据编码类型而定,可能是1个字节或者是5个字节:
- 1字节:如果前一个数据项占用字节数小于254,那么
<previous length>就只用一个字节来表示,这个字节的值就是前一个数据项的占用字节数。 - 5字节:如果前一个数据项占用字节数大于等于254,那么
<previous length>就用5个字节来表示,其中第1个字节的值是254(作为这种情况的一个标记),而后面4个字节组成一个整型值,来真正存储前一个数据项的占用字节数。
上文我们提到,ziplist结束标记<zlend>的值为固定的255。在ziplist的很多操作的实现中,都会根据数据项的第1个字节是不是255来判断当前是不是到达ziplist的结尾了。
2、encoding&cur_entry_length:存储的是编码类型encoding和当前节点的长度cur_entry_length,一种字符串 和另一种是整数。根据第1个字节的不同,有如下不同情况:
- 字符串来编码存储
- 整数来编码存储
三、ziplist节点entry结构
上节中我们讲解了entry的存储结构和编码规则,从ziplist节点的存储结构,我们可以看到zlentry结构和节点在ziplist的真实的存储结构并不是一一对应的。那么我们就来看看ziplist怎么从一段字符数组转换为zlentry结构的?
// 压缩链表结构体
typedef struct zlentry {
// prevrawlen为上一个链表节点占用的长度
// prevrawlensize为存储上一个链表节点的长度数值所需要的字节数
unsigned int prevrawlensize, prevrawlen;
// len为当前链表节点占用的长度
// lensize为存储当前链表节点长度数值所需要的字节数
unsigned int lensize, len;
// 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小
unsigned int headersize;
// 编码方式
unsigned char encoding;
// 压缩链表以字符串的形式保存,该指针指向当前节点起始位置
unsigned char *p;
} zlentry;
为了便于理解我们可以
将第一部分prev_entry_length域看做对prevrawlensize、prevrawlen字段的抽象;
将第二部分cur_entry_length域看做是对lensize、len字段的抽象。
另外,我们经常需要跳过节点的header部分(第一部分和第二部分)读取节点真正存储的数据,所以zlentry结构定义了headersize字段记录节点头部长度。
/* Return a struct with all information about an entry. */
void zipEntry(unsigned char *p, zlentry *e) {
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
}
从二、三章节理解,整个ziplist的存储结构可以总结如下:
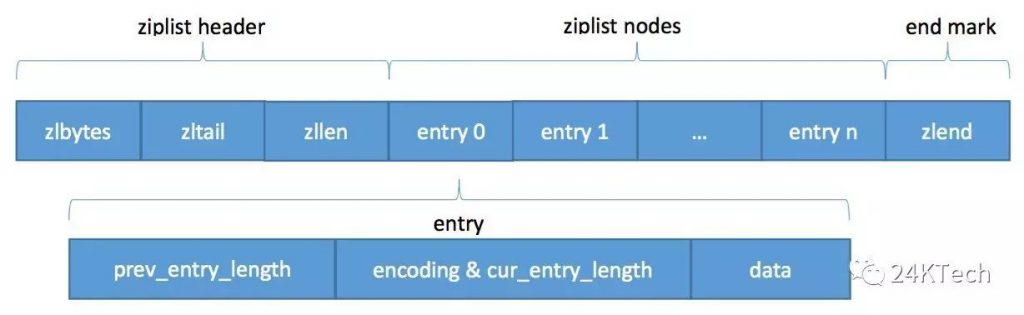
四、hash与ziplist
我们知道hash是Redis中可以用来存储一个对象结构的比较理想的数据类型,一个对象的各个属性,正好对应一个hash结构的各个field。
当hash存储的数据增多,其底层数据结构的实现是会发生变化的,当然存储效率也就不同。在field比较少,各个value值也比较小的时候,hash采用ziplist来实现;而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那些序列化方式相比了。
当我们为某个key第一次执行 hset key field value 命令的时候,Redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
上面的createHashObject函数,出自object.c,它负责的任务就是创建一个新的hash结构。可以看出,它创建了一个type = OBJ_HASH但encoding = OBJ_ENCODING_ZIPLIST的robj对象。
每执行一次hset命令,插入的field和value分别作为一个新的数据项插入到ziplist中(即每次hset产生两个数据项)。
当随着数据的插入,hash底层的这个ziplist就可能会转成dict。那么到底插入多少才会转呢?
我们在看在redis.conf的配置:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
上面配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成dict:
- 当hash中的数据项(即field-value对)的数目超过512的时候,也就是ziplist数据项超过1024的时候(请参考t_hash.c中的
hashTypeSet函数)。 - 当hash中插入的任意一个value的长度超过了64的时候(请参考t_hash.c中的
hashTypeTryConversion函数)。
Redis的hash之所以这样设计,是因为当ziplist变得很大的时候,它有如下几个缺点:
- 每次插入或修改引发的realloc操作会有更大的概率造成内存拷贝,从而降低性能。
- 一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据。
- 当ziplist数据项过多的时候,在它上面查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
五、总结
压缩列表的原理,ziplist并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存拷贝。
转载请注明:学时网 » Redis数据结构之ziplist



