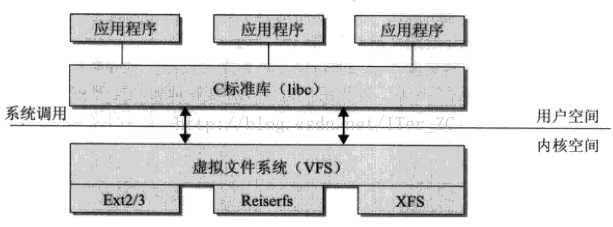
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
-
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
-
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
-
支持通过kafka服务器和消费机集群来分区消息。
-
支持Hadoop并行数据加载。
Kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。
这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。
这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机
制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
下图为kafka的架构图:
1、下载Kafka bin包
下载地址:https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.0/kafka_2.8.0-0.8.0.tar.gz

[plain] view plaincopy
-
> tar xzf kafka-<VERSION>.tgz
-
> cd kafka-<VERSION>
-
> sbt update
-
> sbt package
-
> sbt assembly-package-dependency
这里可能有很多童鞋执行sbt的时候会报找不到这个命令
[plain] view plaincopy
-
No command 'sbt' found, did you mean:
-
Command 'skt' from package 'latex-sanskrit' (main)
-
Command 'sb2' from package 'scratchbox2' (universe)
-
Command 'sbd' from package 'cluster-glue' (main)
-
Command 'mbt' from package 'mbt' (universe)
-
Command 'sbmt' from package 'atfs' (universe)
-
Command 'lbt' from package 'lbt' (universe)
-
Command 'st' from package 'suckless-tools' (universe)
-
Command 'sb' from package 'lrzsz' (universe)
-
sbt: command not found
这个是需要自己安装的,安装包可以到sbt官网下载。我这边用的ubuntu系统,所以我下载了个deb包,官网地址:http://www.scala-sbt.org/
deb包地址:http://repo.scala-sbt.org/scalasbt/sbt-native-packages/org/scala-sbt/sbt/0.13.1/sbt.deb
rpm包地址:http://repo.scala-sbt.org/scalasbt/sbt-native-packages/org/scala-sbt/sbt/0.13.1/sbt.rpm
2、启动服务
官网教程中有启动zookeeper这一项,启动zookeeper之前要配置好zookeeper.properties
[plain] view plaincopy
-
> bin/zookeeper-server-start.sh config/zookeeper.properties
-
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
-
…
由于我这边使用的是独立的zookeeper,所以无需执行以上步骤;
如果想知道zookeeper独立安装步骤,可以查看我的博客http://blog.csdn.net/weijonathan/article/details/8591117
有了zookeeper之后我们启动Kafka服务,但是在这之前我们要先配置好kafka的server.properties文件
将server.properties中的zookeeper.connect配置为你的zookeeper集群地址
[plain] view plaincopy
-
zookeeper.connect=nutch1:2181
接下来启动kafka
[plain] view plaincopy
-
> bin/kafka-server-start.sh config/server.properties
3、创建Topic
创建一个名为“test”只有一个分区,只有一个副本的Topic:
[plain] view plaincopy
-
> bin/kafka-create-topic.sh –zookeeper nutch1:2181 –replica 1 –partition 1 –topic test
运行list topic命令,可以看到Topic列表
[plain] view plaincopy
-
> bin/kafka-list-topic.sh –zookeeper nutch1:2181
4、发送消息
kafka自带的一个命令行客户端,运行后可以输入消息,kafka会将其发送到kafka进群进行消息消费。默认情况下,每一行数据被作为一个消息进行发送。
接下来我们运行producer试试
[plain] view plaincopy
-
> bin/kafka-console-producer.sh –broker-list nutch1:9092 –topic test
-
This is a message
-
This is another message
这里输入This is a message和This is another message
5、启动消费者(consumer)
上面我们通过kafka自带的命令行输入了两行消息,那么我们现在启动消费者看看是否会接收到。
[plain] view plaincopy
-
> bin/kafka-console-consumer.sh –zookeeper nutch1:2181 –topic test –from-beginning
-
This is a message
-
This is another message
可以看到消费者已经对我们上面输入的数据进行处理了;