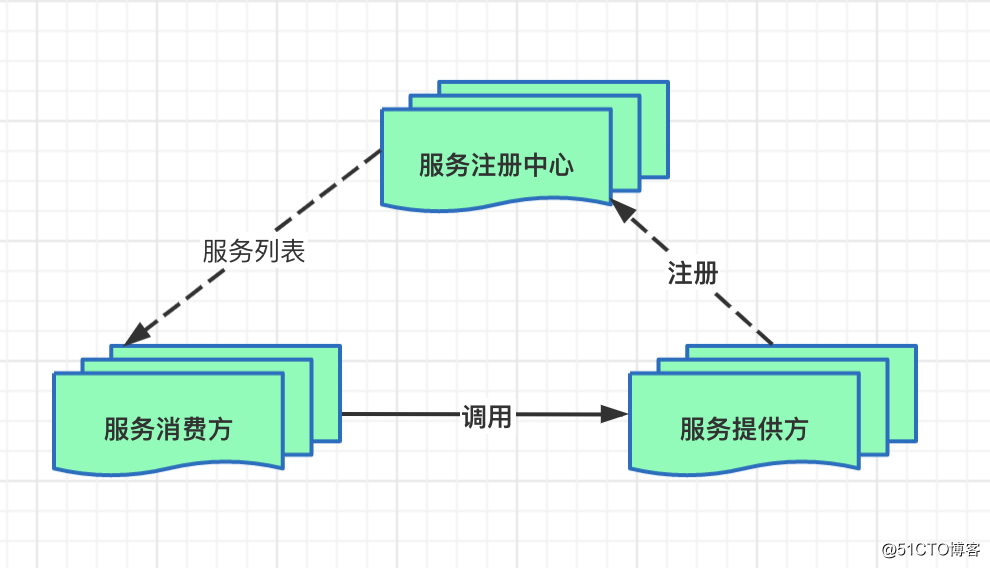
1、背景
说起应用分层,大部分人都会认为这个不是很简单嘛 就controller,service, mapper三层。看起来简单,很多人其实并没有把他们职责划分开,在很多代码中,controller做的逻辑比service还多,service往往当成透传了,这其实是很多人开发代码都没有注意到的地方,反正功能也能用,至于放哪无所谓呗。这样往往造成后面代码无法复用,层级关系混乱,对后续代码的维护非常麻烦。
的确在这些人眼中分层只是一个形式,前辈们的代码这么写的,其他项目代码这么写的,那么我也这么跟着写。
但是在真正的团队开发中每个人的习惯都不同,写出来的代码必然带着自己的标签,有的人习惯controller写大量的业务逻辑,有的人习惯在service中之间调用远程服务,这样就导致了每个人的开发代码风格完全不同,后续其他人修改的时候,一看,我靠这个人写的代码和我平常的习惯完全不同,修改的时候到底是按着自己以前的习惯改,还是跟着前辈们走,这又是个艰难的选择,选择一旦有偏差,你的后辈又维护你的代码的时候,恐怕就要骂人了。
所以一个好的应用分层需要具备以下几点:
- 方便后续代码进行维护扩展;
- 分层的效果需要让整个团队都接受;
- 各个层职责边界清晰。
2、应用分层模型
在项目开发中,一个良好的工程架构是必须的。工程架构就像一个骨架,写代码就是在这个骨架上增添血肉,这个骨架会影响到整体的模块划分,功能划分,即会影响到代码的解耦和聚合,将会很大程度上决定一个项目写得好不好。
这里要分享的是我个人在开发时所采取的工程架构,以及相关的思想。不同的人对于工程架构的理解会不同,实际上也很难分出哪种好,哪种坏,只要符合自己的设计思想,并且能够有效的进行开发,那就是好的一种架构方式。
2.1、分层
我整体上的思想为《阿里巴巴 Java 开发手册》中所描述的分层模型。如下:
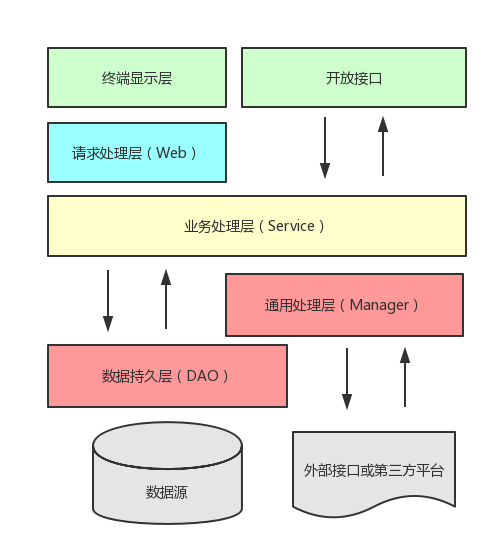
应用分层图
在这里插一嘴哈,在这里我使用的流程图工具是ProcessOn,是一款在线画图工具,非常适合画各种示意图,体验极佳,如果大家想尝试一下,可以使用我的邀请链接注册(阅读原文)使用~
接下来将自底向上的讲解我对各层的理解和设计,还有我自己所增加的层。
2.2、通用工具层
通用工具层其实为对业务无关的,通用的工具类,例如日期处理的工作累,一些数据格式的序列化与反序列化工具。类似于 apache commons 包和 guava 包。
2.3、分层领域模型
领域模型,也就是我们之前常见的各种数据实体,用 DDD 的术语来说,这种在分层模型中的领域模型称为贫血领域模型。 贫血领域模型只作为数据载体,只有 getter/setter 方法,而不包含业务方法。
对于分层领域模型,会进一步进行划分规约,主要也是参考自《阿里巴巴 Java 开发手册》具体如下:
- DO(Data Object) : 数据对象,对数据源数据的映射,如数据库表,ElasticSearch 索引的数据结构。所在包一般命名为 data 。
- DTO(Data Transfer Object) : 数据传输对象,业务层向外传输的对象。如果在某个业务中需要多次查询获取不同的数据对象,最后将会把这多个数据对象组合成一个 DTO 并对外传输。所在包命名为 dto 。
- BO(Business Object) : 业务对象,由 Service 层输出的封装业务逻辑的对象。即对象除了数据外,还会包含一定的业务逻辑,也可以说是充血领域模型。但是我一般不会使用。
- AO(Application Object) : 应用对象,在 Web 层与 Service 层之间抽象的复用对象模型,极为贴近展示层,复用度不高。比较少用。
- VO(View Object) : 显示层对象,通常是 Web 向模板渲染引擎层传输的对象。现在的项目多数为前后端分离,后端只需要返回 JSON ,那么可以理解为 JSON 即是需要渲染成的“模板”。我一般会将这类对象命名为 xxxResponse ,所在包命名为 response 。
- Query : 数据查询对象,数据查询对象,各层接收上层的查询请求。其实一般用于 Controller 接受传过来的参数,可以将其都命名为 xxxQuery ,而我个人习惯将放在 request body 的参数(即 @RequestBody)包装为 xxxRequest ,而如果使用表单传输过来的参数(即 @RequestParam)包装为 xxxForm ,并分别放在包 request 和包 form 下。
其实贫血领域模型只是作为数据的载体,在一开始我觉得没必要进行具体的分类,基本上都是往一个包内丢,但是当项目规模上来后,各种各样的数据实体开始增加,慢慢的变得混乱。对数据对象的分类是为了更好的定义每个数据的作用以及在后续能够快速的定位到对应的数据对象。
2.4、Helper
开发中会遇到一些很基础的,通用的业务逻辑,例如我们可能会根据每个用户的信息生成一个唯一的 account id 。又或者说有一个用户排名的需求,我们将从用户的相关信息中计算出一个分数,从而根据这个分数进行排名。那么这时候我们可能会将这些逻辑写在 User 数据对象或是其他相应对应的数据对象下。 而我个人来说,不希望数据对象包含业务逻辑,所以我会将这些通用的业务逻辑都抽出来,放到 Manager 中进行统一管理。如会将生成 account id 的逻辑放在 AccountIdGenerator 中,将计算排名分数的逻辑放在 RankCalculator 中。 我将这些类都归为 Helper ,用于提供底层的业务计算逻辑。而为什么不放在通用工具层中呢?因为这些 Helper 其实都是依赖于特定的领域,即特定的业务。而通用工具类则是业务无关的,任何系统,只要有需要都可以引用。
2.5、DAO
DAO 就不用过多解释了,数据访问对象,用于对数据库的访问。但是我个人不会将 DAO 只局限于数据库,对于不同的数据源的交互,如 HBase ,ElasticSearch ,本地缓存甚至 Redis 我都会定义相对应的 DAO 进行访问。 这样的定义,其实是想将数据 CURD 的逻辑和业务逻辑进行分离,将获 CRUD 封装在 DAO 中,业务逻辑即放在业务层中。
之前接手了一个项目,项目将 Redis 视为中间件,将相关的逻辑都封装在 xxxRedisService 中,包括 CRUD 和一些业务逻辑。随着项目的发展,一些其实可以归类到一起的业务,变得有些放在了 RedisService 中,一些放在了业务层的 Service 中,可想而知十分混乱,还导致了一些 BUG 的出现。
2.6、Service 和 Manager
Service 的作用不用多说明,为具体业务逻辑的封装层。
具体要说明的是 Manager ,《阿里巴巴 Java 开发手册》中定义如下:
- 对第三方平台封装的层,预处理返回结果及转化异常信息
- 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理
- 与 DAO 层交互,对多个 DAO 的组合复用
可以将 Manager 理解为对通用逻辑的封装,避免 Service 与 Service 进行相互调用,以及对通用逻辑的管理。
在开发中,我们经常会遇到 AService 中的某个业务可以提供给 BService 调用,从而让 BService 调用 AService 的方法,认为是 Service 之间具有共同的业务。其实 Service 之间没有共同的业务,而是具备通用的逻辑,这时应该将其抽离出来放在 Manager 中。无论何种工程架构都好,我都不赞同 Service 与 Service 之间的相互调用。
在实际开发中,我会对 Manager 进行更细一点的划分。大致将其分为用于项务类,所封装的是由 Service 下沉的通用业务。 而另一种则是一些偏向于工具、计算的类,例如某个业务使用了策略模式,所编写的策略类则属于这一类。 我会将业务类的用 @Service 注释,而偏工具类的则用 @Component 注释。这样做的原因还是避免业务之间的相互调用,相互耦合。
这里可能会想,为什么不将 Helper 的逻辑也放在 Manager 层中?原因在于 Helper 的逻辑比 Manager 更加基础,有可能在 DAO 中都会调用 Helper 的相关逻辑,如果放在 Manager 中,就会出现底层依赖上层的问题。
2.7、接口层
最后的一层,则是暴露给外部调用的层。可以是 Spring 体系中的 Controller ,也可以是 gRPC 。 这一层将组织、调用我们所定义的 Service ,进行业务处理。
3、分层模型的优点以及缺点
无论什么工程架构,都会有其优点以及缺点,在选择工程架构时,其实就是对优点缺点的衡量。
3.1、优点
其实无论什么架构,特别是对业务工程来说,最希望架构带来的是解耦以及内聚。 通过分层,在一定程度上对项目内的各个模块进行了解耦内聚,依赖关系十分明确,再怎么写,只要符合规约,总是上层依赖于下层。而且分层的规约十分简单,在多人协作的情况下大部分情况都可以很好的遵守规约。
3.2、缺点
简单是一个优点,也是一个缺点。分层虽然在一定程度上进行了解耦,但是粒度十分粗,只要不出现下层依赖上层的情况,都可以认为是符合规约的,在这种情况下,很容易导致代码的分散、功能的碎片化,明明是同一类业务功能的代码,却分散在多个类,多个层次之间。在项目不断迭代时变得巨大时,慢慢就会变得混乱,然后就是一轮重构。 归根到底就是太松懈了,导致开发人员很容易就是在项目中随便找个地方写,还很容易导致由大量的复制粘贴所产生重复代码。
在学校开设的软件工程课中,设计一个系统,首先是组织架构的了解,然后从中抽出数据流,然后再在数据流中抽出业务流,进行根据业务流进行开发。而采用分层模型的化,往往在数据流中就可以开始开发,采用分层模型的话,每个业务其实可以简单的抽象成数据在各层之间的流动。 这可以说是一个优点,简化了业务的理解,实现快速的开发,我在比较紧的排期下也由这么做过,扫一眼业务,构思好数据流的流动后就动手了。但这也是一个很严重的缺点,我见过不少功能性 BUG ,就是由于对业务的不充分理解所导致的,而且由于没有对业务流程充分理解后就开发,后续的扩展和修复,看起来就是不断的修修补补。
上面,我除了《阿里巴巴 Java 开发手册》所写的内容外,还添加了不少细节,其实所想要做的就是尽量减少这种功能碎片化的问题。
4、与充血领域模型的对比
既然是说工程架构,就不得不提 DDD 这一个概念。
为什么我说的是“与充血领域模型的对比”而不是“与 DDD 的对比”呢?是因为 DDD 是比分层模型更加高层的一种概念,它是一个产品服务,整个团队开发的一种指导思想,而不是一种工程代码上的规约。
DDD 可以分为两大方向,一个是战略层面上的,即之前提到的是一种开发的指导思想,定义、划分服务的领域,规定统一语言提高沟通效率等,这也是可以用于使用分层领域模型的项目开发中的。如果要与分层模型对比的话,其实是 DDD 的战术层面,即充血领域模型。
充血领域模型其实是回归于面向对象的思想。在目前的分层模型中,哪怕是用 Java 这种面向对象的语言去写,其实总体上还是一种过程式的编程,在 DDD 中称为事务脚本。
充血领域模型是重领域,轻 Service 的。以之前生成 account id 以及排名的例子,在充血领域模型中,User 类将会有 generateAccountId 方法和 ranking 方法来完成这一逻辑。 完全的面向对象,就可以充分的发挥面向对象的特性。面向对象的特性在书上为:继承、多态,封装。前两者能够实现归一化,使模块泛化通用,封装即会使模块划分明确,能够很好的实现解耦和内聚。比起分层模型,使用充血领域模型可以很好的解决上面提到的代码分散,碎片化的问题。
充血领域模型的优点是面向对象的优点,但是面向对象的缺点也成为这种模型的缺点。首先,万物皆可抽象在我看来就是伪命题,因为现实世界中总有事务是难以进行抽象的,或者抽象起来不优雅,总是有一种硬是抽象的感觉。 在知乎中有一个很好的回答,描述了面向对象的弊端
相信很多人在初接触 DDD 时,都会去搜索充血领域模型实践的例子。其实在学校学习 Java Web 开发时,书本中写道的 MVC 结构其实在一定程度上也是充血领域模型,Model 除了是数据的载体外,还包含业务逻辑,通过 Controller 对 Model 的选择以及调用完成业务。假如用这种结构开发,当项目庞大后,我觉得首先遇到的问题应该就是依赖问题,复杂的业务必然牵扯到各方各面,自然也就有复杂的依赖关系产生,甚至会有为了完成业务而产生很“脏”的实现,这是难以避免的。
我个人觉得充血领域模型目前还是只适合于个人,很小的团队中使用,例如 2 到 3 个人的团队,因为抽象本身就是一个非常复杂的过程,随着需求迭代,之前的抽象还不一定正确,如果在较为多人的多人协作中,各种奇奇怪怪的写法都会出现,必然也会有随便找个“地”写的情况出现,这种情况比在分层模型中更为致命。
5、总结
还是那句话,工程架构无分好坏,只有适合与不适合,问题的来与在于业务的复杂,计算机始终在某些方面难以映射到现实世界。所以我个人建议好好的理解好自己目前所用到的工程架构,尽量做到扬长避短。
本文分享自微信公众号 – 程序员小明(coderxinqiji),作者:小明
原文出处及转载信息见文内详细说明,如有侵权,请联系 yunjia_community@tencent.com 删除。
原始发表时间:2019-10-06
本文参与腾讯云自媒体分享计划,欢迎正在阅读的你也加入,一起分享。
转载请注明:学时网 » 优秀的代码都是如何分层的?