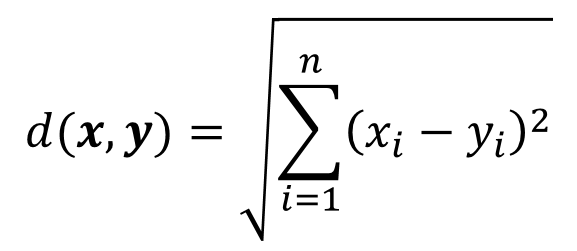1. 引言
小麦同窗是个吃货+技术宅,平日里就喜欢拿着手机地图点点按按来查询一些好玩的东西。某一天到北海公园游玩,肚肚饿了,因而乎打开手机地图,搜索北海公园附近的餐馆,并选了其中一家用餐。 饱暖思yin欲的麦叔饭后思考地图后台如何根据本身所在位置查询来查询附近餐馆的呢?苦思冥想了半天,小麦想出了个方法:计算所在位置P与北京全部餐馆的距离,而后返回距离<=1000米的餐馆。小得意了一下子,小麦发现北京的餐馆何其多啊,这样计算不得了,因而想了,既然知道经纬度了,那它应该知道本身在西城区,那应该计算所在位置P与西城区全部餐馆的距离啊,机机运用了
饱暖思yin欲的麦叔饭后思考地图后台如何根据本身所在位置查询来查询附近餐馆的呢?苦思冥想了半天,小麦想出了个方法:计算所在位置P与北京全部餐馆的距离,而后返回距离<=1000米的餐馆。小得意了一下子,小麦发现北京的餐馆何其多啊,这样计算不得了,因而想了,既然知道经纬度了,那它应该知道本身在西城区,那应该计算所在位置P与西城区全部餐馆的距离啊,机机运用了递归的思想,想到了西城区也不少餐馆啊,应该计算所在位置P与所在街道全部餐馆的距离,这样计算量又小了,效率也提高了。mysql
小麦的计算思想很朴素,就是经过过滤的方法来减少参与计算的餐馆数目,从某种角度上讲,机机在使用索引技术。web
一提到索引,你们脑子里立刻浮现出B树索引,由于大量的数据库(如MySQL、oracle、PostgreSQL等)都在使用B树。B树索引本质上是对索引字段进行排序,而后经过相似二分查找的方法进行快速查找,即它要求索引的字段是可排序的,通常而言,可排序的是一维字段,好比时间、年龄、薪水等等。可是对于空间上的一个点(二维,包括经度和纬度),如何排序呢?又如何索引呢?解决的方法不少,下文介绍一种方法来解决这一问题。算法
思想:若是能经过某种方法将二维的点数据转换成一维的数据,那样不就能够继续使用B树索引了嘛。那这种方法真的存在嘛,答案是确定的。目前很火的GeoHash算法就是运用了上述思想,下面咱们就开始GeoHash之旅吧。sql
2. 感性认识
先来两个干货,在线查看GPS某个区域的GeoHash值。数据库
1. http://geohash.gofreerange.com/

2. http://www.geohash.cn/
跟更好用些 缓存
缓存
3. 通俗说
GeoHash将二维的经纬度转换成字符串,好比下图展现了北京9个区域的GeoHash字符串,分别是WX4ER,WX4G二、WX4G3等等,每个字符串表明了某一矩形区域。也就是说,这个矩形区域内全部的点(经纬度坐标)都共享相同的GeoHash字符串,这样既能够保护隐私(只表示大概区域位置而不是具体的点),又比较容易作缓存,好比左上角这个区域内的用户不断发送位置信息请求餐馆数据,因为这些用户的GeoHash字符串都是WX4ER,因此能够把WX4ER看成key,把该区域的餐馆信息看成value来进行缓存,而若是不使用GeoHash的话,因为区域内的用户传来的经纬度是各不相同的,很难作缓存。 字符串越长,表示的范围越精确。如图所示,5位的编码能表示10平方公里范围的矩形区域,而6位编码能表示更精细的区域(约0.34平方公里)
字符串越长,表示的范围越精确。如图所示,5位的编码能表示10平方公里范围的矩形区域,而6位编码能表示更精细的区域(约0.34平方公里) 字符串类似的表示距离相近(特殊状况后文阐述),这样能够利用字符串的前缀匹配来查询附近的POI信息。以下两个图所示,第一个在城区,第二个在郊区,城区的GeoHash字符串之间比较类似,郊区的字符串之间也比较类似,而城区和郊区的GeoHash字符串类似程度要低些。
字符串类似的表示距离相近(特殊状况后文阐述),这样能够利用字符串的前缀匹配来查询附近的POI信息。以下两个图所示,第一个在城区,第二个在郊区,城区的GeoHash字符串之间比较类似,郊区的字符串之间也比较类似,而城区和郊区的GeoHash字符串类似程度要低些。
 经过上面的介绍咱们知道了
经过上面的介绍咱们知道了GeoHash就是一种将经纬度转换成字符串的方法,而且使得在大部分状况下,字符串前缀匹配越多的距离越近,回到咱们的案例,根据所在位置查询来查询附近餐馆时,只须要将所在位置经纬度转换成GeoHash字符串,并与各个餐馆的GeoHash字符串进行前缀匹配,匹配越多的距离越近。微信
4. GeoHash算法的步骤
下面以北海公园附近随便一个位置为例介绍GeoHash算法的计算步骤,先用百度 GPS反定位系统查找看下经纬度。 纬度=116.395371,经度=39.931957。oracle
纬度=116.395371,经度=39.931957。oracle
根据经纬度计算GeoHash二进制编码
地球纬度区间是[-90,90], 北海公园的纬度是39.928167,能够经过下面算法对纬度39.928167进行逼近编码:编辑器
- 区间[-90,90]进行二分为[-90,0),[0,90],称为左右区间,能够肯定39.928167属于右区间[0,90],给标记为1;
- 接着将区间[0,90]进行二分为 [0,45),[45,90],能够肯定39.928167属于左区间 [0,45),给标记为0;
- 递归上述过程39.928167老是属于某个区间[a,b]。随着每次迭代区间[a,b]总在缩小,并愈来愈逼近39.928167;
- 若是给定的纬度x(39.928167)属于左区间,则记录0,若是属于右区间则记录1,这样随着算法的进行会产生一个序列1011100,序列的长度跟给定的区间划分次数有关。
39.928167 根据纬度算编码函数
| bit | min | mid | max |
|---|---|---|---|
| 1 | -90.000 | 0.000 | 90.000 |
| 0 | 0.000 | 45.000 | 90.000 |
| 1 | 0.000 | 22.500 | 45.000 |
| 1 | 22.500 | 33.750 | 45.000 |
| 1 | 33.750 | 39.375 | 45.000 |
| 0 | 39.375 | 42.188 | 45.000 |
| 0 | 39.375 | 40.7815 | 42.188 |
| 0 | 39.375 | 40.07825 | 40.7815 |
| 1 | 39.375 | 39.726625 | 40.07825 |
| 1 | 39.726625 | 39.9024375 | 40.07825 |
同理,地球经度区间是[-180,180],能够对经度116.389550进行编码。根据经度算编码
| bit | min | mid | max |
|---|---|---|---|
| 1 | -180 | 0.000 | 180 |
| 1 | 0.000 | 90 | 180 |
| 0 | 90 | 135 | 180 |
| 1 | 90 | 112.5 | 135 |
| 0 | 112.5 | 123.75 | 135 |
| 0 | 112.5 | 118.125 | 123.75 |
| 1 | 112.5 | 115.3125 | 118.125 |
| 0 | 115.3125 | 116.71875 | 118.125 |
| 1 | 115.3125 | 116.015625 | 116.71875 |
| 1 | 116.015625 | 116.3671875 | 116.71875 |
组码
经过上述计算,纬度产生的编码为10111 00011,经度产生的编码为11010 01011。偶数位放经度,奇数位放纬度,把2串编码组合生成新串:11100 11101 00100 01111。最后使用用0-九、b-z(去掉a, i, l, o)这32个字母进行base32编码,首先将11100 11101 00100 01111转成十进制,对应着2八、2九、四、15,十进制对应的编码就是wx4g。同理,将编码转换成经纬度的解码算法与之相反,具体再也不赘述。
5. GeoHash Base32编码长度与精度
能够看出,当geohash base32编码长度为8时,精度在19米左右,而当编码长度为9时,精度在2米左右,编码长度须要根据数据状况进行选择。
1、经纬度距离换算
在纬度相等的状况下:
- 经度每隔0.00001度,距离相差约1米;
- 每隔0.0001度,距离相差约10米;
- 每隔0.001度,距离相差约100米;
- 每隔0.01度,距离相差约1000米;
- 每隔0.1度,距离相差约10000米。
在经度相等的状况下:
- 纬度每隔0.00001度,距离相差约1.1米;
- 每隔0.0001度,距离相差约11米;
- 每隔0.001度,距离相差约111米;
- 每隔0.01度,距离相差约1113米;
- 每隔0.1度,距离相差约11132米。
6. GeoHash算法
上文讲了GeoHash的计算步骤,仅仅说明是什么而没有说明为何?为何分别给经度和维度编码?为何须要将经纬度两串编码交叉组合成一串编码?本节试图回答这一问题。
以下图所示,咱们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是相似于Z的曲线,当咱们递归的将各个块分解成更小的子块时,编码的顺序是自类似的(分形),每个子快也造成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优势是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码类似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,好比0111与1000,编码是相邻的,但距离相差很大。  除Peano空间填充曲线外,还有不少空间填充曲线,如图所示,其中效果公认较好是
除Peano空间填充曲线外,还有不少空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为何GeoHash不选择Hilbert空间填充曲线呢?多是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
7. 使用注意点
1. 临界问题
因为GeoHash是将区域划分为一个个规则矩形,并对每一个矩形进行编码,这样在查询附近POI信息时会致使如下问题,好比红色的点是咱们的位置,绿色的两个点分别是附近的两个餐馆,可是在查询的时候会发现距离较远餐馆的GeoHash编码与咱们同样(由于在同一个GeoHash区域块上),而较近餐馆的GeoHash编码与咱们不一致。这个问题每每产生在边界处。
解决的思路很简单,咱们查询时,除了使用定位点的GeoHash编码进行匹配外,还使用周围8个区域的GeoHash编码,这样能够避免这个问题。
2. 注意点
咱们已经知道现有的GeoHash算法使用的是Peano空间填充曲线,这种曲线会产生突变,形成了编码虽然类似但距离可能相差很大的问题,所以在查询附近餐馆时候,首先筛选GeoHash编码类似的POI(point of interest)点,而后进行实际距离计算。
3. 使用心得
GeoHash只是空间索引的一种方式,特别适合点数据,而对线、面数据采用R树索引更有优点(可为何须要空间索引)。
GeoHash值能够区分精度,位数越多,精度越高,表达的地理位置越精细;如一位的GeoHash值把地球划分为32个矩形,8位的geohash值把地球划分为32^8个小矩形
适合根据某个经纬度坐标position计算出GeoHash值,而后和数据库中精度更高的GeoHash值作前缀比较
8.空间索引
常见问题:如何根据本身所在位置查询来查询附近50米的POI(point of interest,好比商家、景点等)呢(图1a)? 每一个POI都有经纬度信息,用图1b的SQL语句在mySQL中创建了POI_spatial的表,其中lat和lng两个字段来表明
每一个POI都有经纬度信息,用图1b的SQL语句在mySQL中创建了POI_spatial的表,其中lat和lng两个字段来表明纬度和经度。为后续分析方便起见,我人造了40万个POI数据。
方法一:暴力方法
该方法的思路很直接:计算位置与全部POI的距离,并保留距离小于50米的POI。
插句题外话,计算经纬度之间的距离不能像求欧式距离那样平方开根号,由于地球是个不规整的球体(图2a),普通计算适合都是默认按最简单的完美球体假设,两点之间的距离函数应该如图2b所示。
 该方法的复杂度为:40万*距离函数。咱们将球体距离函数写为mysql存储过程distance,以后咱们执行查询操做(图3),发现花费了4.66秒。
该方法的复杂度为:40万*距离函数。咱们将球体距离函数写为mysql存储过程distance,以后咱们执行查询操做(图3),发现花费了4.66秒。
方法二:矩形过滤方法
该方法采用逐步细化的方式,通常分为两部:
- 先用矩形框过滤(图4a),判断一个点在矩形框内很简单,只要进行两次判断(LtMin<lat<LtMax; LnMin<lng<LnMax),落在矩形框内的POI个数为n(n<<40万);
- 用球面距离公式计算位置与矩形框内n个POI的距离(图4b),并保留距离小于50米的POI
矩形过滤方法的复杂度:40万矩形过滤函数 + n距离函数(n<<40万)。 根据这个思路咱们执行SQl查询(图5)(注:经度或纬度每隔0.001度,距离相差约100米,由此推算出矩形左下角和右上角坐标),发现过滤后正好剩下两个POI。
根据这个思路咱们执行SQl查询(图5)(注:经度或纬度每隔0.001度,距离相差约100米,由此推算出矩形左下角和右上角坐标),发现过滤后正好剩下两个POI。
此查询花费了0.36秒,相比于方法一查询时间大大下降,可是对于一次查询来讲仍是很长。时间长的缘由在于遍历了40万次。
方法三:B树对经度或纬度创建索引
方法二耗时的缘由在于执行了遍历操做,为了避免进行遍历,咱们天然想到了索引。咱们对纬度进行了B树索引。
alter table poi_spatial add index latindex(lat);alter table poi_spatial add index lngindex(lng);此方法包括三个步骤:
- 经过B树快速找到某纬度范围的POI(图6a),个数为m(m<40万),复杂度为Log(40万)*过滤函数;
- 在步骤a过滤获得的m个POI中查找某经度范围的POI(图6b),个数为n(n<m),复杂度为m*过滤函数;
- 用球面距离公式计算位置与步骤b获得的n个POI的距离(图6c),并保留距离小于50米的POI
 执行SQL查询(图7),发现时间已经大大下降,从方法2的0.36秒降低到0.01秒
执行SQL查询(图7),发现时间已经大大下降,从方法2的0.36秒降低到0.01秒
3、B树能索引空间数据吗?
这时候有人会说了:方法三效果如此好,可以知足咱们附近POI查询问题啊,看来B树用来索引空间数据也是能够的嘛!那么B树真的可以索引空间数据吗?
- 只能对经度或纬度索引(一维索引),与指望的不符 咱们期待的是快速找出落在某一空间范围的POI(如矩形)(图8a),而不是快速找出落在某纬度或经度范围的POI(图8b),想象一下,我要查询北京某区的POI,可是B树索引不只给我找出了北京的,还有与北京同一维度的天津、大同、甚至国外城市的POI,当数据量很大时,效率很低。

- 当数据是多维,好比三维(x,y,z),B树怎么索引?好比z多是高程值,也多是时间。有人会说B树其实能够对多个字段进行索引,但这时须要指定优先级,造成一个组合字段,而空间数据在各个维度方向上不存在优先级,咱们不能说纬度比经度更重要,也不能说纬度比高程更重要。
- 当空间数据不是点,而是线(道路、地铁、河流等),面(行政区边界、建筑物等),B树怎么索引?对于面来讲,它由一系列首尾相连的经纬度坐标点组成,一个面可能有成百上千个坐标,这时数据库怎么存储,B树怎么索引,这些都是问题。
既然传统的索引不能很好的索引空间数据,咱们天然须要一种方法能对空间数据进行索引,即空间索引。
参考
Java实现GPS范围查找
浙大大佬通俗说GPS
本文分享自微信公众号 – sowhat1412(sowhat9094)。
若有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一块儿分享。
转载请注明:学时网 » GeoHash核心原理解析