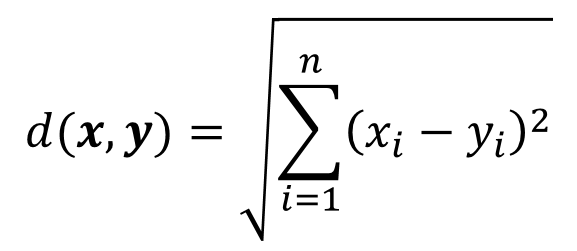知乎上链接:https://zhuanlan.zhihu.com/p/115690499
目前工业界常用的召回排序模型主要有:
召回模型
(1)基于内容的召回CB(Content–Base)
使用item之间的相似性来推荐与用户喜欢的item相似的item。
(2)基于协同过滤的召回CF (Collaborative filtering)
协同过滤主要可以分为基于用户的协同过滤、 基于物品的协同过滤、基于模型的协同过滤(如矩阵分解als、svd、svd++等等)。
(3)基于关联规则召回
基于关联规则召回通常有频繁模式挖掘,如Apriori、Fpgrowth等模型
(4)基于深度学习模型的召回
基于深度学习模型的召回也称之为embedding向量召回(每个user和item在一个时刻只用一个embedding向量去表示)的一些经典方法,其主要思想为:将user和item通过DNN映射到同一个低维度向量空间中,然后通过高效的检索方法去做召回。常见的模型有:NCF模型、Youtube DNN召回、 双塔模型召回、MIND模型等等。
(5)基于图模型召回
基于图模型召回有二部图挖掘,如simrank;Graph Embedding模型,如DeepWalk、node2vec等模型。
(6)基于用户画像的召回
基于用户画像的召回主要根据用户画像如品牌偏好、颜色偏好、价格偏好等偏好信息召回。
(7)基于热度召回
排序模型
(1)基于传统的机器学习模型
基于传统的机器学习模型如LR、SVM等模型。
(2)基于树模型
基于树模型有gbdt、RandomForest、xgboost等。
(3)基于交叉特征模型
基于交叉特征模型有fm、ffm、lr+gbdt等
(4)基于深度学习模型的排序
基于深度学习模型的排序有widedeep、dcn、deepfm等。
实现
目前包含召回和排序各阶段,各种算法的实现,均可运行;由于工作闲余时间写的,有点乱,后续有时间好好整理,深度学习相关的模型改成TF2.0
一、 什么是推荐系统?
引用百度百科的一段解释就是:“利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。”
在这个数据过载的时代,信息的消费者需要从海量的信息中找到自己所需要的信息,信息的生产者要让自己生产的信息在海量的信息中脱颖而出,这时推荐系统就应运而生了。对用户而言,推荐系统不需要用户提供明确的目标;对物品而言,推荐系统解决了2/8现象的问题(也叫长尾效应),让小众的物品可以展示到需要它们的用户面前。二、推荐系统要解决的问题?
1、帮助用户找到想要的物品 如:书籍、电影等
2、可以降低信息过载
3、有利于提高站点的点击率/转化率
4、有利于对用户进行深入了解,为用户提供个性化服务
三、推荐系统的发展趋势?
推荐系统的研究大致可以分为三个阶段,第一阶段是基于传统的服务,第二阶段是基于目前的社交网络的服务,第三阶段是即将到来的物联网。这其中产生了很多基础和重要的算法,例如协同过滤(包括基于用户的和基于物品的)、基于内容的推荐算法、混合式的推荐算法、基于统计理论的推荐算法、基于社交网络信息(关注、被关注、信任、知名度、信誉度等)的过滤推荐算法、群体推荐算法、基于位置的推荐算法。其中基于邻域的协同过滤推荐算法是推荐系统中最基础、最核心、最重要的算法,该算法不仅在学术界得到较为深入的研究,而且在业界也得到非常广泛的应用,基于邻域的算法主要分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法,除此之外,基于内容的推荐算法应用也非常广泛等等,因此下文将对涉及推荐系统的常用算法进行详细介绍。
1、基于流行度的推荐算法
2、基于协同过滤的推荐算法(UserCF与ItemCF)
3、基于内容的推荐算法
4、基于模型的推荐算法
5、基于混合式的推荐算法
四、基于流行度的推荐算法
基于流行度的算法非常简单粗暴,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
注:独立访客(UV)、访问次数(VV)两个指标有什么区别?
① 访问次数(VV):记录1天内所有访客访问了该网站多少次,相同的访客有可能多次访问该网站,且访问的次数累加。
② 独立访客(UV):记录1天内所有访客访问了该网站多少次,虽然相同访客能多次访问网站,但只计算为1个独立访客。
③ PV访问量(Page View):即页面访问量,每打开一次页面或者刷新一次页面,PV值+1。
1、优点:该算法简单,适用于刚注册的新用户
2、缺点:无法针对用户提供个性化的推荐
3、改进:基于该算法可做一些优化,例如加入用户分群的流行度进行排序,通过把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
五、基于用户的协同过滤推荐算法
当目标用户需要推荐时,可以先通过兴趣、爱好或行为习惯找到与他相似的其他用户,然后把那些与目标用户相似的用户喜欢的并且目标用户没有浏览过的物品推荐给目标用户。
1、基于用户的CF原理如下:
① 分析各个用户对物品的评价,通过浏览记录、购买记录等得到用户的隐性评分;
② 根据用户对物品的隐性评分计算得到所有用户之间的相似度;
③ 选出与目标用户最相似的K个用户;
④ 将这K个用户隐性评分最高并且目标用户又没有浏览过的物品推荐给目标用户。2、优点:
① 基于用户的协同过滤推荐算法是给目标用户推荐那些和他有共同兴趣的用户喜欢的物品,所以该算法推荐较为社会化,即推荐的物品是与用户兴趣一致的那个群体中的热门物品;
② 适于物品比用户多、物品时效性较强的情形,否则计算慢;
③ 能实现跨领域、惊喜度高的结果。3、缺点:
① 在很多时候,很多用户两两之间的共同评分仅有几个,也即用户之间的重合度并不高,同时仅有的共同打了分的物品,往往是一些很常见的物品,如票房大片、生活必需品;
② 用户之间的距离可能变得很快,这种离线算法难以瞬间更新推荐结果;
③ 推荐结果的个性化较弱、较宽泛。4、改进:
① 两个用户对流行物品的有相似兴趣,丝毫不能说明他们有相似的兴趣,此时要增加惩罚力度;
② 如果两个用户同时喜欢了相同的物品,那么可以给这两个用户更高的相似度;
③ 在描述邻居用户的偏好时,给其最近喜欢的物品较高权重;
④ 把类似地域用户的行为作为推荐的主要依据。六、基于物品的协同过滤推荐算法
当一个用户需要个性化推荐时,举个例子由于我之前购买过许嵩的《梦游计》这张专辑,所以会给我推荐《青年晚报》,因为很多其他用户都同时购买了许嵩的这两张专辑。
1、基于物品的CF原理如下:
① 分析各个用户对物品的浏览记录;
② 依据浏览记录分析得出所有物品之间的相似度;
③ 对于目标用户评价高的物品,找出与之相似度最高的K个物品;
④ 将这K个物品中目标用户没有浏览过的物品推荐给目标用户2、优点:
① 基于物品的协同过滤推荐算法则是为目标用户推荐那些和他之前喜欢的物品类似的物品,所以基于物品的协同过滤推荐算法的推荐较为个性,因为推荐的物品一般都满足目标用户的独特兴趣。
② 物品之间的距离可能是根据成百上千万的用户的隐性评分计算得出,往往能在一段时间内保持稳定。因此,这种算法可以预先计算距离,其在线部分能更快地生产推荐列表。
③ 应用最广泛,尤其以电商行业为典型。
④ 适于用户多、物品少的情形,否则计算慢
⑤ 推荐精度高,更具个性化
⑥ 倾向于推荐同类商品3、缺点:
① 不同领域的最热门物品之间经常具有较高的相似度。比如,基于本算法,我们可能会给喜欢听许嵩歌曲的同学推荐汪峰的歌曲,也就是推荐不同领域的畅销作品,这样的推荐结果可能并不是我们想要的。
② 在物品冷启动、数据稀疏时效果不佳
③ 推荐的多样性不足,形成信息闭环4、改进:
① 如果是热门物品,很多人都喜欢,就会接近1,就会造成很多物品都和热门物品相似,此时要增加惩罚力度;
② 活跃用户对物品相似度的贡献小于不活跃的用户;
③ 同一个用户在间隔很短的时间内喜欢的两件商品之间,可以给予更高的相似度;
④ 在描述目标用户偏好时,给其最近喜欢的商品较高权重;
⑤ 同一个用户在同一个地域内喜欢的两件商品之间,可以给予更高的相似度。七、基于内容的推荐算法
协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,而根本不会考虑到物品本身的属性,而基于内容的算法会考虑到物品本身的属性。
根据用户之前对物品的历史行为,如用户购买过什么物品、对什么物品收藏过、评分过等等,然后再根据计算与这些物品相似的物品,并把它们推荐给用户。例如某用户之前购买过许嵩的《寻宝游戏》,这可以说明该用户可能是一个嵩鼠,这时就可以给该用户推荐一些许嵩的其他专辑或著作。
1、基于内容的推荐算法的原理如下:
① 选取一些具有代表性的特征来表示每个物品
② 使用用户的历史行为数据分析物品的这些特征,从而学习出用户的喜好特征或兴趣,也即构建用户画像
③ 通过比较上一步得到的用户画像和待推荐物品的画像(由待推荐物品的特征构成),将具有相关性最大的前K个物品中目标用户没有浏览过的物品推荐给目标用户2、优点:
① 是最直观的算法
② 常借助文本相似度计算
③ 很好地解决冷启动问题,并且也不会囿于热度的限制3、缺点:
① 容易受限于对文本、图像、音视频的内容进行描述的详细程度
② 过度专业化(over-specialisation),导致一直推荐给用户内容密切关联的item,而失去了推荐内容的多样性。
③ 主题过于集中,惊喜度不足八、基于模型的推荐算法
基于模型的推荐算法会涉及到一些机器学习的方法,如逻辑回归、朴素贝叶斯分类器等。基于模型的算法由于快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是需要这种算法达到更好的效果,则需要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而由于新闻的时效性,系统也需要反复更新线上的数学模型,以适应变化。
九、基于混合式的推荐算法
现实应用中,其实很少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的计算环节中运用不同的算法来混合,达到更贴合自己业务的目的。
十、推荐结果列表处理
1、当推荐算法计算得出推荐结果列表之后,我们往往还需要对结果进行处理。比如当推荐的内容里包含敏感词汇、涉及用户隐私的内容等等,就需要系统将其筛除;
2、若多次推荐后用户依然对某个物品毫无兴趣,就需要将这个物品降低权重,调整排序;
3、有时系统还要考虑话题多样性的问题,同样要在不同话题中筛选内容。
十一、推荐结果评估
当一个推荐算法设计完成后,一般需要用查准率(precision),查全率(recall),点击率(CTR)、转化率(CVR)、停留时间等指标进行评价。
查准率(precision):推荐给用户且用户喜欢的物品在推荐列表中的比重
查全率(recall):推荐给用户且用户喜欢的物品在用户列表中的比重
点击率(CTR):实际点击了的物品/推荐列表中所有的物品
转化率(CVR):购买了的物品/实际点击了的物品
————————————————
版权声明:本文为CSDN博主「Jack-He」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Vensmallzeng/article/details/101343117
算法和模型是推荐系统的核心,直接决定了推荐效果的好坏。在推荐系统中,算法要从两个方面来考虑:算法本身准确性和算法的效率。相对算法准确性,推荐系统工程化更关注的是算法效率。算法和模型层面主要包含如图所示。
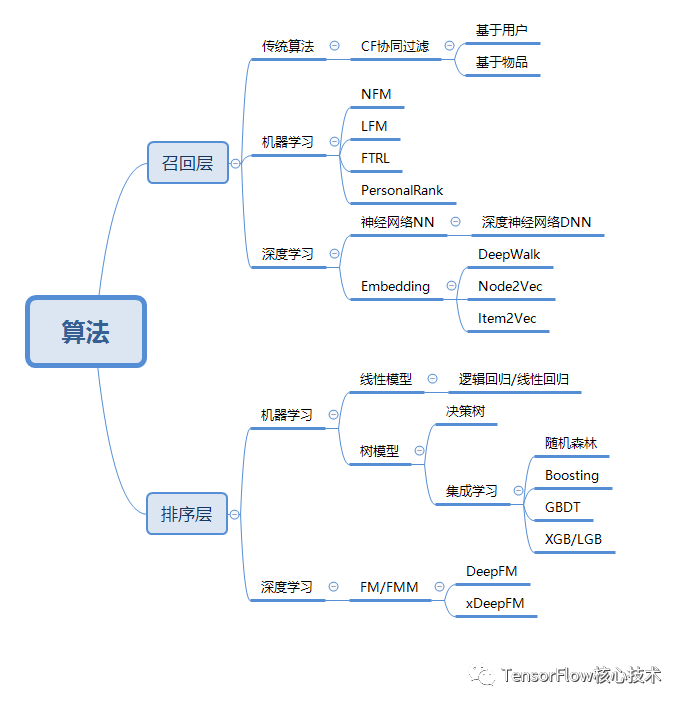
从推荐算法的理论来讲,主要可以从召回层和排序层两个方面来说,虽然召回层和排序层都是使用算法和模型来做,但是针对于不用的阶段,所用的模型也有一定的差别。
在召回层中,我们又可以分为3类方法,即传统算法、机器学习和深度学习模型。
所谓的传统算法就是利用传统推荐系统理论中所采用的算法,例如计算用户之间的相似度、物品之间的相似度等,而这两类算法从大体上来讲,都可以用协同过滤算法来表示,只不过一个是基于用户的协同过滤算法,一个是基于物品的协同过滤算法。
所谓的机器学习模型指使用机器学习相关算法来得到召回层结果的方法,例如NMF(Nonnegative Matrix Factor,非负矩阵分解)算法、LFM模型(Latent Factor Model,基于潜在隐因子模型)、FTRL(Follow The Regularized Leader)算法、PersonalRank算法等。
所谓的深度学习模型指使用深度学习相关算法来得到召回层结果的方法,包括深度神经网络(DNN)和Embedding等方法。
而在排序层中,我们也可以使用机器学习和深度学习两种方式来对召回结果进行排序,这里的排序一般采用点击率预估,并将预估得到的概率降序排序取前N得到最终的排序结果。
在使用机器学习进行排序层排序时,我们也可以将其分成2个大类,分别为线性模型和树模型,实际上,在真正的使用过程中,我们会将这两类模型结合起来使用。
- 在线性模型中主要使用逻辑回归作为主要的排序算法,而逻辑回归又属于线性回归的一种变形,因此,要想学习好逻辑回归,就得对线性回归有一定的了解。
- 树模型是排序算法中用得最多的一种模型的统称,在排序层中常用的树模型又分为决策树模型和集成学习模型,常用在推荐系统中的有随机森林、Boosting、GBDT、XGB、LGB。
虽然排序层的机器学习算法会被分为线性模型和树模型两种,但是进行排序时一般将二者结合使用,其中常见的组合方式就是使用GBDT+LR的方式进行点击率预测和排序层的排序。
而使用深度学习模型进行点击率预测和排序层排序也是推荐系统中常用的方式,尤其对于大量的数据和特征,渐渐成为目前各大企业的主流排序方式,常见方式是DeepFM和xDeepFM。DeepFM顾名思义就是深度模型(Deep)和因子分解机(FM)结合使用。而xDeepFM是DeepFM的升级版,主要改进的是DeepFM模型中的DCN模型的缺点。
转载请注明:学时网 » 常用推荐算法实现(包括召回和排序)