前言
最近遇到几个系统 young gc 时间比较长,在 young gc 长的同时,系统负载也随时升高,因此熟读GC日志以及了解一些Jvm常见调优是必要的。
收获
看完应该有如下收获
- 熟悉young GC日志每一行啥意思(会看)。
- 了解一些关键GC调优参数(采坑)。
日志分析
// GC原因,新生代minor GC。
2019-11-09T10:14:42.496+0800: 143830.361: [GC pause (G1 Evacuation Pause) (young)
//survivor大小及对象年龄最大值是15
Desired survivor size 67108864 bytes, new threshold 15 (max 15).
- age 1: 21372336 bytes, 21372336 total
- age 2: 5495736 bytes, 26868072 total
- age 3: 30424 bytes, 26898496 total
- age 4: 116344 bytes, 27014840 total
- age 5: 22704 bytes, 27037544 total
- age 6: 81712 bytes, 27119256 total
- age 7: 17824 bytes, 27137080 total
- age 8: 172736 bytes, 27309816 total
- age 9: 348672 bytes, 27658488 total
- age 10: 361192 bytes, 28019680 total
- age 11: 153648 bytes, 28173328 total
- age 12: 37056 bytes, 28210384 total
- age 13: 81800 bytes, 28292184 total
- age 14: 6272 bytes, 28298456 total
- age 15: 31096 bytes, 28329552 total
// 发生minor GC和full GC时,所有相关region都是要回收的。而发生并发GC时,会根据目标停顿时间动态选择部分垃圾对并多的Region回收,这一步就是选择Region。
// pending_cards是关于RSet的Card Table。
// predicted base time是预测的扫描card table时间。
143830.362: [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 13047, predicted base time: 104.33 ms, remaining time: 0.00 ms, target paus
// 这一步是添加Region到collection set,新生代一共496个Region,16个幸存区Region,预计收集时间是3.45 ms。
143830.362: [G1Ergonomics (CSet Construction) add young regions to CSet, eden: 496 regions, survivors: 16 regions, predicted young region time: 3.45 ms]
// 这一步是对上面两步的总结。预计总收集时间107.78ms。
143830.362: [G1Ergonomics (CSet Construction) finish choosing CSet, eden: 496 regions, survivors: 16 regions, old: 0 regions, predicted pause time: 107.78 ms
//
2019-11-09T10:14:42.611+0800: 143830.477: [SoftReference, 0 refs, 0.0136201 secs]2019-11-09T10:14:42.625+0800: 143830.490: [WeakReference, 2 refs, 0.0165891 s
// Parallel Time: 并行收集任务在运行过程中引发的STW(Stop The World)时间,从新生代垃圾收集开始到最后一个任务结束,共花费93.6ms
// GC Workers: 有28个线程负责垃圾收集,通过参数-XX:ParallelGCThreads设置,这个参数的值的设置,跟CPU有关,默认值 ParallelGCThreads=8+( Processor - 8 ) ( 5/8 )
[Parallel Time: 93.6 ms, GC Workers: 28]
// 第一个垃圾收集线程开始工作时JVM启动后经过的时间(min);最后一个垃圾收集线程开始工作时JVM启动后经过的时间(max);diff表示min和max之间的差值。理想情况
[GC Worker Start (ms): Min: 143830362.2, Avg: 143830362.7, Max: 143830363.5, Diff: 1.4]
// 扫描root集合(线程栈、JNI、全局变量、系统表等等)花费的时间,扫描root集合是垃圾收集的起点,尝试找到是否有root集合中的节点指向当前的收集集合(CSet)
[Ext Root Scanning (ms): Min: 2.3, Avg: 8.2, Max: 16.0, Diff: 13.6, Sum: 229.4]
// 每个分区都有自己的RSet,用来记录其他分区指向当前分区的指针,如果RSet有更新,G1中会有一个post-write barrier管理跨分区的引用——新的被引用的card会被标记为di
[Update RS (ms): Min: 0.0, Avg: 1.4, Max: 4.0, Diff: 4.0, Sum: 39.4]
// Processed Buffers,这表示在Update RS这个过程中处理多少个日志缓冲区。
[Processed Buffers: Min: 0, Avg: 17.0, Max: 67, Diff: 67, Sum: 475]
//扫描每个新生代分区的RSet,找出有多少指向当前分区的引用来自CSet。
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 1.6]
// 扫描代码中的root节点(局部变量)花费的时间
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
//在疏散暂停期间,所有在CSet中的分区必须被转移疏散,Object Copy就负责将当前分区中存活的对象拷贝到新的分区。
[Object Copy (ms): Min: 0.0, Avg: 7.6, Max: 85.5, Diff: 85.4, Sum: 212.1]
//当一个垃圾收集线程完成任务时,它就会进入一个临界区,并尝试帮助其他垃圾线程完成任务(steal outstanding tasks),min表示该垃圾收集线程什么时候尝试terminat
[Termination (ms): Min: 0.0, Avg: 75.2, Max: 79.0, Diff: 79.0, Sum: 2106.8]
// 如果一个垃圾收集线程成功盗取了其他线程的任务,那么它会再次盗取更多的任务或再次尝试terminate,每次重新terminate的时候,这个数值就会增加
[Termination Attempts: Min: 1, Avg: 1.4, Max: 2, Diff: 1, Sum: 39]
// 垃圾收集线程在完成其他任务的时间
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 1.0]
// 展示每个垃圾收集线程的最小、最大、平均、差值和总共时间
[GC Worker Total (ms): Min: 91.6, Avg: 92.5, Max: 93.3, Diff: 1.7, Sum: 2590.3]
// GC Worker End:min表示最早结束的垃圾收集线程结束时该JVM启动后的时间;max表示最晚结束的垃圾收集线程结束时该JVM启动后的时间。理想情况下,你希望它们快速结
[GC Worker End (ms): Min: 143830455.1, Avg: 143830455.2, Max: 143830455.5, Diff: 0.4]
// 新生代GC中的一些任务
[Code Root Fixup: 0.1 ms] //释放用于管理并行垃圾收集活动的数据结构,应该接近于0,该步骤是线性执行的;
[Code Root Purge: 0.0 ms] //清理更多的数据结构,应该很快,耗时接近于0,也是线性执行
[Clear CT: 0.5 ms] //清理card table
//一些其他的拓展功能
[Other: 114.6 ms]
[Choose CSet: 0.0 ms] //选择要进行回收的分区放入CSet(G1选择的标准是垃圾最多的分区优先,也就是存活对象率最低的分区优先)
[Ref Proc: 109.9 ms] // 处理Java中的各种引用——soft、weak、final、phantom、JNI等等。
[Ref Enq: 0.6 ms] // 遍历所有的引用,将不能回收的放入pending列表
[Redirty Cards: 0.4 ms] //在回收过程中被修改的card将会被重置为dirty
[Humongous Register: 0.1 ms]// JDK8u60提供了一个特性,巨型对象可以在新生代收集的时候被回收——通过G1ReclaimDeadHumongousObjectsAtYoungGC设置,默认为true。
[Humongous Reclaim: 0.0 ms] //做下列任务的时间:确保巨型对象可以被回收、释放该巨型对象所占的分区,重置分区类型,并将分区还到free列表,并且更新空闲空间大小
[Free CSet: 0.9 ms]// 将要释放的分区还回到free列表。
// 展示了不同代的大小变化,以及堆大小的自适应调整
// Eden: 992.0M(992.0M)->0.0B(982.0M)
(1)当前新生代收集触发的原因是Eden空间满了,分配了992M,使用了992M;
(2)所有的Eden分区都被疏散处理了,在新生代结束后Eden分区的使用大小成为了0.0B;
(3)Eden分区的大小缩小为982.0M;
// Survivors: 32.0M->42.0M:由于年轻代分区的回收处理,survivor的空间从32.0M涨到42.0M;
// Heap: 2304.3M(4096.0M)->1322.8M(4096.0M)]
(1)在本次垃圾收集活动开始的时候,堆空间整体使用量是2304.3M,堆空间的最大值是4096.0M;
(2)在本次垃圾收集结束后,堆空间的使用量是1322.8M,最大值保持不变。
[Eden: 992.0M(992.0M)->0.0B(982.0M) Survivors: 32.0M->42.0M Heap: 2304.3M(4096.0M)->1322.8M(4096.0M)]
// 本次新生代垃圾收集的时间
// user=2.81 :垃圾收集线程在新生代垃圾收集过程中消耗的CPU时间,这个时间跟垃圾收集线程的个数有关,可能会比real time大很多;
// sys=0.17 :内核态线程消耗的CPU时间
// real=0.21:本次垃圾收集真正消耗的时间;
[Times: user=2.81 sys=0.17, real=0.21 secs]
2019-11-09T10:14:42.705+0800: 143830.570: Total time for which application threads were stopped: 0.2183659 seconds, Stopping threads took: 0.0012684 seconds
// 当GC发生时,每个线程只有进入了SafePoint才算是真正挂起,也就是真正的停顿,这个日志的含义是整个GC过程中STW的时间,配置了-XX:+PrintGCApplicationStoppedTime这
// 重点:第一个0.0091676 seconds 是JVM启动后的秒数,第二个 0.0007286 seconds是JVM发起STW的开始到结束的时间。特别地,如果是GC引发的STW,这条内容会紧挨着出现在G
// 这里想搞清楚? 请移步: https://juejin.cn/post/6844903991952801806
2019-11-09T10:14:42.795+0800: 143830.660: Total time for which application threads were stopped: 0.0091676 seconds, Stopping threads took: 0.0007286 seconds
关键参数调优
注意: 下面都是简单介绍,想深入每一个参数需要一个小时的学习。
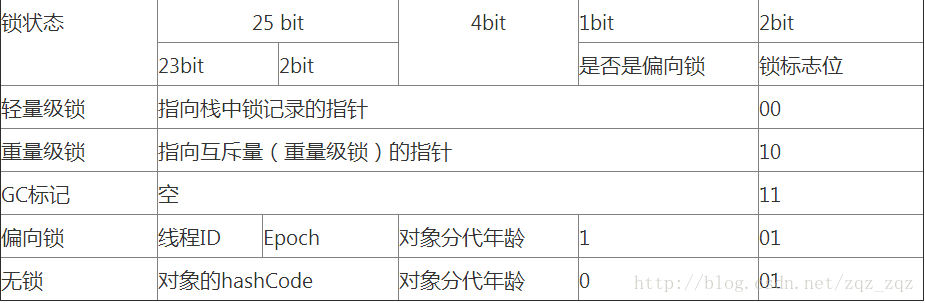
-XX:-UseBiasedLocking
JDK1.6开始默认打开的偏向锁,会尝试把锁赋给第一个访问它的线程,取消同步块上的synchronized原语。如果始终只有一条线程在访问它,就成功略过同步操作以获得性能提升。但一旦有第二条线程访问这把锁,JVM就要撤销偏向锁恢复到未锁定线程的状态,如果打开安全点日志,可以看到不少RevokeBiasd的纪录,像GC一样Stop The World的干活,虽然只是很短的停顿,但对于多线程并发的应用,取消掉它反而有性能的提升,所以建议在系统出现瓶颈的时候,做去偏向锁优化。
-XX:AutoBoxCacheMax
Integer i=3;这语句有着 int自动装箱成Integer的过程,JDK默认只缓存 -128 ~ +127的Integer 和 Long,超出范围的数字就要即时构建新的Integer对象。高并发的情况下,拆箱装箱的性能损耗不可忽略,因此建议调大这个配置,比如2w。
-XX:ParallelGCThreads
由于GC操作会暂停所有的应用程序线程,JVM为了尽量缩短停顿时间就必须尽可能地利用更多的CPU资源。这意味着,默认情况下,JVM会在机器的每个CPU上运行一个线程,最多同时运行8个。
一旦达到这个上限,JVM会调整算法,每超出5/8个CPU启动一个新的线程。所以总的线程数就是(这里的N代表CPU的核心数): ParallelGCThreads = 8 + ((N – 8) * 5/8)
有时候使用这个算法估算出来的线程数目会偏大。如果应用程序使用一个较小的堆(譬如大小为1 GB)运行在一个八颗CPU的机器上,使用4个线程或者6个线程处理这个堆可能会更高效。在一个128颗CPU的机器上,启动83个垃圾收集线程可能也太多了,除非系统使用的堆已经达到了最大上限。
-XX:+HeapDumpOnOutOfMemoryError
在Out Of Memory,JVM快死掉的时候,输出Heap Dump到指定文件,但在容器环境(或者混部)下,在普通硬盘上会造成20秒以上的硬盘IO跑满,也是个十足的恶邻,影响了同一宿主机上所有其他的服务。
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m
扩容会导致停顿,对下游影响比较大,之前support踩过这个坑,一定要观察metaspace的大小,不够了就赶紧调整。
-XX:+PrintGCApplicationStoppedTime
GC时间不长,但是下游频繁超时,这种就有可能不是gc造成的停顿了,非GC导致的停顿,比如取消偏向锁,code deoptimization等等,打开-XX:+PrintGCApplicationStoppedTime这个参数
注意:安全点日志不能一直打开:
- 安全点日志默认输出到stdout,一是stdout日志的整洁性,二是stdout所重定向的文件如果不在/dev/shm,可能被锁。
- 对于一些很短的停顿,比如取消偏向锁,打印的消耗比停顿本身还大。
- 安全点日志是在安全点内打印的,本身加大了安全点的停顿时间。
所以安全日志应该只在问题排查时打开。 如果在生产系统上要打开,再再增加下面四个参数: -XX:+UnlockDiagnosticVMOptions -XX: -DisplayVMOutput -XX:+LogVMOutput -XX:LogFile=/dev/shm/vm.log 打开Diagnostic(只是开放了更多的flag可选,不会主动激活某个flag),关掉输出VM日志到stdout,输出到独立文件,/dev/shm目录(内存文件系统)。
-XX:+PerfDisableSharedMem
项目中的日志异步写了,当磁盘IO高的时候,服务日志会丢弃,那么你有没有想到GC日志的写入会不会影响JVM的性能呢,会不会对GC时间造成影响呢,答案是肯定的,当磁盘IO高,且正在刷page cache,这个时候就有可能造成停顿。
重点关注:real时间是不是超长,正常real时间要远远小于user时间(大概十分之一),当前系统是不是正在flush pageCache 到磁盘,当符合这两种情况的时候就及有可能是IO影响的。
-Xss
-Xss256k:在堆之外,线程占用栈内存,默认每条线程为1M。存放方法调用出参入参的栈、局部变量、标量替换后的局部变量等,有人喜欢设小点节约内存开更多线程。但内存够也就不必要设小,有人喜欢再设大点,特别是有JSON解析之类的递归调用时不能设太小。
-XX:ReservedCodeCacheSize
JIT编译后二进制代码的存放区,满了之后就不再编译,默认245m。当codeCache满了,程序将会出现明显的卡顿,服务能力下降,此时JVM会打印出一条警告消息,并切换到interpreted-only 模式:JIT编译器被停用,字节码将不再会被编译成机器码。因此,应用程序将继续运行,但运行速度会降低一个数量级,直到有人注意到这个问题。
// 当服务极度卡顿,可以怀疑这里,可以通过反证法验证是否出现过这个日志,来确认是不是这个问题
`Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled`
复制代码-XX:+AlwaysPreTouch
JAVA进程启动的时候,虽然我们可以为JVM指定合适的内存大小,但是这些内存操作系统并没有真正的分配给JVM,而是等JVM访问这些内存的时候,才真正分配,这样会造成以下问题。
- GC的时候,新生代的对象要晋升到老年代的时候,需要内存,这个时候操作系统才真正分配内存,这样就会加大young gc的停顿时间。
- 可能存在内存碎片的问题。
因此可以考虑开启这个参数,服务启动直接开辟这些内存,配置这个参数需要看实际情况,必须保证不出现overcommit的情况,保证有足够的实际内存可以分配给每一个服务,例子:R大-AlwaysPreTouch
Memory Overcommit的意思是操作系统承诺给进程的内存大小超过了实际可用的内存, 详细分析:Linux overcommit
-XX:+UseStringDeduplication
JVM去重, 可以节省JVM的空间, 但是有可能增加GC的时间.
开启String去重XX:+UseStringDeduplication的利与弊 \ 聊聊G1 GC的String Deduplication
-XX:+ParallelRefProcEnabled
并行的处理Reference对象,如WeakReference,默认为false,除非在GC log里出现Reference处理时间较长的日志,否则效果不会很明显,但我们总是要JVM尽量的并行,所以设了也就设了。同理还有-XX:+CMSParallelInitialMarkEnabled,JDK8已默认开启,但小版本比较低的JDK7甚至不支持。
未完待续。。。
作者:丶Joy丶
链接:https://juejin.cn/post/6844903991990714375
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
转载请注明:学时网 » GC日志逐行分析+关键性能优化参数分析