http://www.infoq.com/cn/articles/jingdong-11-11-commodity-search-system-architecture-design
一、 京东商品搜索简介
京东商品搜索引擎是搜索推荐部自主研发的商品搜索引擎,主要功能是为海量京东用户
提供精准、快速的购物体验。虽然只有短短几年的时间,我们的搜索引擎已经经过了多次618店庆和双11的考验,目前已经能够与人们日常使用的如谷
歌、百度等全文搜索引擎相比,我们的产品与其有相通之处,比如涵盖亿级别商品的海量数据、支持短时超高并发查询、又有自己的业务特点:
-
海量的数据,亿级别的商品量;
-
高并发查询,日PV过亿;
-
请求需要快速响应。
搜索已经成为我们日常不可或缺的应用,很难想象没有了Google、百度等搜索引擎,互联网会变成什么样。京东站内商品搜索对京东,就如同搜索引擎
对互联网的关系。他们的共同之处:1. 海量的数据,亿级别的商品量;2. 高并发查询,日PV过亿;3.
请求需要快速响应。这些共同点使商品搜索使用了与大搜索类似的技术架构,将系统分为:1. 离线信息处理系统;2. 索引系统;3.
搜索服务系;4.反馈和排序系统。
同时,商品搜索具有商业属性,与大搜索有一些不同之处:1. 商品数据已经结构化,但散布在商品、库存、价格、促销、仓储等多个系统;2.
召回率要求高,保证每一个正常的商品均能够被搜索到;3.
为保证用户体验,商品信息变更(比如价格、库存的变化)实时性要求高,导致更新量大,每天的更新量为千万级别;4.
较强的个性化需求,由于是一个相对垂直的搜索领域,需要满足用户的个性化搜索意图,比如用户搜索“小说”有的用户希望找言情小说有的人需要找武侠小说有的
人希望找到励志小说。另外不同的人消费能力、性别、对配送时间的忍耐程度、对促销的偏好程度以及对属性比如“风格”、“材质”等偏好不同。以上这些需要有
比较完善的用户画像系统来提供支持。
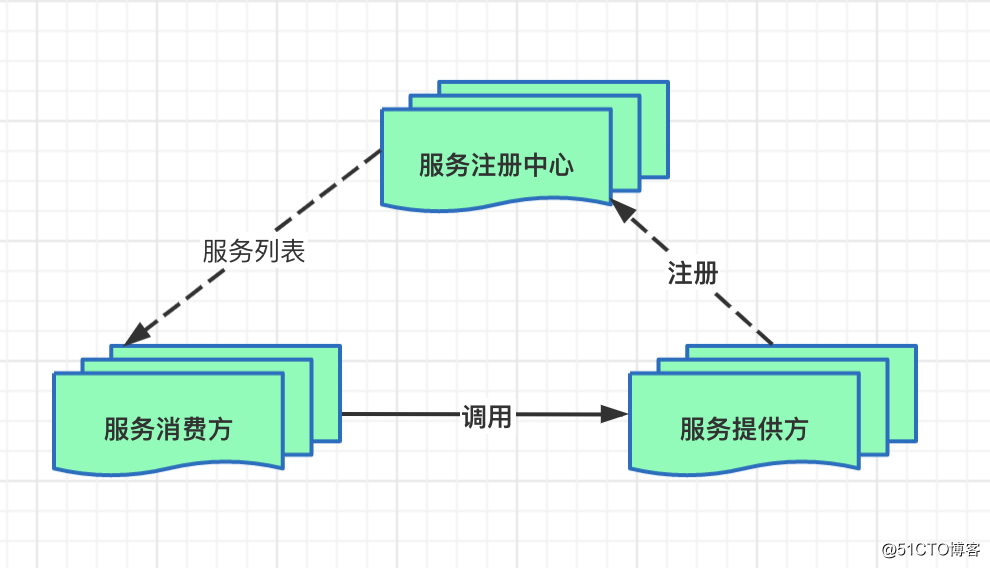
一、总体架构图
(点击放大图像)

搜索服务集群:由很多个merger节点组成的集群。接收到查询query后,将请求通过qp触发有策略地下发到在线检索服务集群和其他服务集群,并对各个服务的返回结果进行合并排序,然后调用detail server包装结果,最终返回给用户。
query processor server:搜索query意图识别服务。
在线检索服务集群:由很多个searcher节点组成,每个searcher列对应一个小分片索引(包含全量数据和实时增量数据)。
detail server:搜索结果展示服务。
索引生产端:包含全量和增量数据生产,为在线检索服务集群提供全量索引和实时索引数据。
二、 离线信息处理系统
由于商品数据分布在不同的异构数据库当中有KV有关系型数据库,需要将这些数据抽取到京东搜索数据平台中,这分为全量抽取和实时抽取。
对于全量索引,由于商品数据散布于多个系统的库表中,为了便于索引处理,对多个系统的数据在商品维度进行合并,生成商品宽表。然后在数据平台上,使用MapReduce对商品数据进行清洗,之后进行离线业务逻辑处理,最终生成一份全量待索引数据。
对于实时索引,为了保证数据的实时性,实时调用各商品信息接口获取实时数据,将数据合并后采用与全量索引类似的方法处理数据,生成增量待索引数据。
三、 索引系统
此系统是搜索技术的核心,在进入这个系统之前,搜索信息仍然是以商品维度进行存储的。索引系统负责生成一种以关键字维度进行存储的信息,一般称之为倒排索引。
此系统对于全量和增量的处理是一致的,唯一的区别在于待处理数据量的差异。一般情况下,全量数据索引由于数据量庞大,采用hadoop进行;实时数据量小,采用单机进行索引生产。
四、 搜索服务系统
搜索服务系统是搜索真正接受用户请求并响应的系统。这个系统最初只有1列searcher组成在线检索服务。由于用户体验的需要,首先增加
Query
Processor服务,负责查询意图分析,提升搜索的准确性。随着访问量的增长,接着增加缓存模块,提升请求处理性能。接着随着数据量(商品量)的增
长,将包装服务从检索服务中独立出去,成为detail
server服务。数据量的进一步增长,对数据进行类似数据库分库分表的分片操作。这时候,在线检索服务由多个分片的searcher列组成。自然而然,
需要一个merger服务,将多个分片的结果进行合并。至此,搜索基础服务系统完备。
之后,无论是搜索量的增长或者数据量的增长,都可以通过扩容来满足。对于618、1111之类的搜索量增长,可通过增加每个searcher列服务器的数量来满足。而对于商品数据的不断增加,只需要对数据做更多的分片,相应地增加searcher列来满足。
搜索服务系统内部的处理流程如下:
(点击放大图像)

在这个流程中,缓存模块和拉取结果模块非常稳定。而排序模块和在线业务逻辑处理模块经常需要改动。架构需要稳定,高效和通用。排序业务特点是实验模
型多,开发迭代速度快,讲求效果。为了解决这一冲突,需要将排序业务与架构分离,以动态链接库的方式集成到搜索整体架构中,具体包括文本策略和其他策略两
个维度的相关性,文本策略相关性集成在searcher当中;其他策略相关性(包括反馈,个性化和业务调权等等)集成在merger当中。实现架构与排序
业务各司其职,互不影响干扰。
(点击放大图像)

排序与架构分离
五、 反馈和排序系统
反馈系统主要包含用户行为数据的实时收集、加工,并将数据存储到数据集市当中,并对这些数据进行特征提取,排序最主要考核的线上指标是UV价值和转
化率,所以还会利用这些数据根据优化目标构建起标注数据。然后基于机器学习的排序系统会针对特征构建出模型。京东排序模型是每天更新的训练之前大概半年的
数据。京东搜索在基于模型的排序基础之上,上层还会有一层规则引擎,比如保障店铺和品牌的多样性,以及京东战略扶持的品牌等都通过业务引擎来实现。一般基
于机器学习的排序模型需要较长期的投入但是模型更加健壮不容易被作弊手段找到漏洞,并且可以让转化率和UV价值可持续的提升。
规则引擎主要是为了快速反应市场的变化,起到立竿见影的效果。二者一个像中药一个像西药,中西结合疗效好。
六、针对今年双11的搜索系统性能优化
1.故障秒级切换
今年搜索集群做到了三机房部署,任何一个机房出现断网、断电等问题可以秒级将流量切换到其它机房。并且搜索的部分应用部署到了弹性云上,可以进行动态扩容。
2.大促期间索引数据实时更新
每年大促由于商品内容等信息更改频繁,涉及千万级的索引写操作,今年针对索引结构进行了调整彻底消灭掉了索引更新存在的一切锁机制,商品新增和修改操作变为链式更新。使大促期间商品的索引更新达到了妙极。
3.大促期间的个性化搜索不降级
往年大促期间由于流量在平时5倍以上,高峰流量会在平时的7倍,为了保障系统稳定,个性化搜索都进行了降级处理。今年针对搜索的缓存进行了针对性的
优化,实现了三级缓存结构。从底向上分别是针对term的缓存,相关性计算缓存和翻页缓存。最上层的翻页缓存很多时候会被用户的个性化请求击穿,但是底层
的相关性缓存和term缓存的结果可以起到作用,这样不至于使CPU负载过高。
七、 京东在电商搜索方面产品和技术的创新
1. 个性化搜索
个性化之前的搜索对于同一个查询,不同用户看到的结果是完全相同的。这可能并不符合所有用户的需求。在商品搜索中,这个问题尤为特出。因为商品搜索的用户可能特别青睐某些品牌、价格、店铺的商品,为了减少用户的筛选成本,需要对搜索结果按照用户进行个性化展示。
个性化的第一步是对用户和商品分别建模,第二步是将模型服务化。有了这两步之后,在用户进行查询时,merger同时调用用户模型服务和在线检索服务,用
户模型服务返回用户维度特征,在线检索服务返回商品信息,排序模块运用这两部分数据对结果进行重排序,最后给用户返回个性化结果。
2. 整合搜索
用户在使用搜索时,其目的不仅仅是查找商品,还可能查询服务、活动等信息。为了满足这一类需求,首先在Query
Processor中增加对应意图的识别。第二步是将服务、活动等一系列垂直搜索整合并服务化。一旦QP识别出这类查询意图,就条用整合服务,将对应的结
果返回给用户。
3、情感搜索
情感搜索在于尽可能满足更多的搜索意图,这需要在后台构建一个强大的知识库体系。比如从海里评论中挖掘有意义的标签“成像效果好的相机”、“聚拢效
果好的胸罩”、“适合送丈母娘”等,将这些信息一同构建到索引中去比如搜索“适合送基友的礼物”结合搜索意图分析相关的结果可以搜索出来。另外也可以从外
部网站抓取有价值信息辅助构建知识库体系。
4、图像检索
很多时候用户并不知道如何描述一个商品。通过搜索意图分析、情感分析可以尽可能挖掘搜索意图,很多时候用户根本无法描述,比如在超市看到一个进口食
品或者一件时尚的衣服,可以通过拍照检索迅速在网上找到并比较价格,另外看到同事穿着一件比较喜欢的衣服也可以通过拍照检索来找到。目前京东正在开始展开
这方面的开发。离线方面主要通过CNN算法,对图片进行主题提取、提取相似特征、相同特征提取。引擎端主要是和搜索引擎类似的技术。图像搜索未来将可以开
辟一个新的电商购物入口。京东目前正在研发新的图像检索引擎。
转载请注明:学时网 » 京东11.11:商品搜索系统架构设计