一、引言
HBase其存储和读写的高性能,作为Nosql数据库的一员,HBase查询只能通过其Rowkey来查询(Rowkey用来表示唯一一行记录),Rowkey设计的优劣直接影响读写性能。HBase中的数据是按照Rowkey的ASCII字典顺序进行全局排序的,有伙伴可能...
water
3年前 (2022-09-08) 1807℃ 0评论
1喜欢
Superset介绍及使用说明Superset简介Apache Superset是Airbnb开源的数据挖掘平台。支持丰富的数据源连接,多种可视化方式,并能够对用户实现细粒度的权限控制。该工具主要特点是可自助分析、自定义仪表盘、分析结果可视化(导出)、用户/角色权限控制,还集成...
water
3年前 (2021-11-29) 3150℃ 0评论
2喜欢
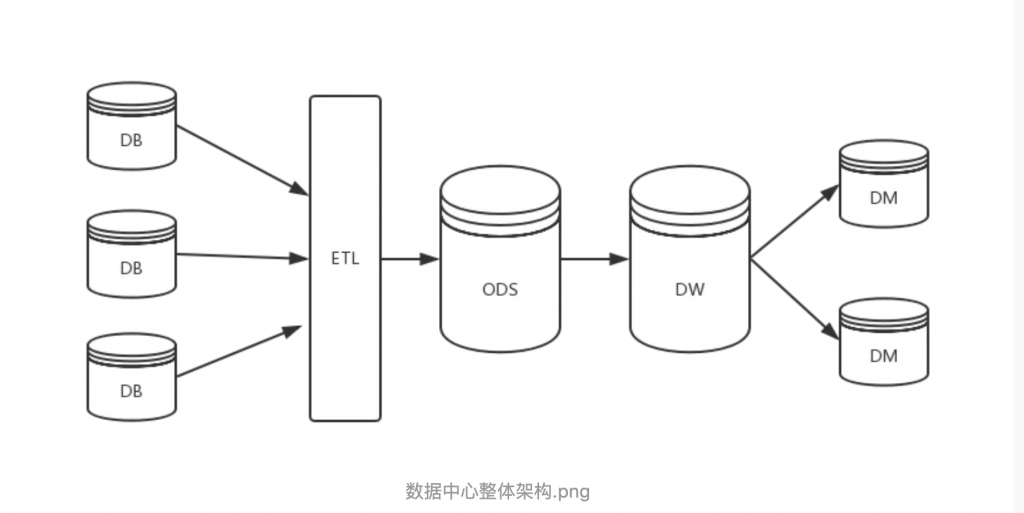
在具体分析数据仓库之前先看下一下数据中心的整体架构以及数据流向
DB 是现有的数据来源,可以为mysql、SQLserver、文件日志等,为数据仓库提供数据来源的一般存在于现有的业务系统之中。ETL的是 Extract-Transform-Load 的缩写,用来描...
water
4年前 (2020-12-31) 2638℃ 0评论
4喜欢
1、环境
cdh5.12.3
spark2 2.3.0
2、需要本地地洞spark2-shell用于环境测试
错误一:
Error: A JNI error has occurred, please check your installation ...
water
5年前 (2020-05-19) 2547℃ 0评论
6喜欢
Parquet、Avro、ORC格式
相同点
基于Hadoop文件系统优化出的存储结构
提供高效的压缩
二进制存储格式
文件可分割,具有很强的伸缩性和并行处理能力
使用schema进行自我描述
属于线上格式,可以在Hadoop节点之间传递数据
不同点
...
water
6年前 (2019-09-04) 3986℃ 0评论
2喜欢
技术最终为业务服务,没必要一定要追求先进性,各个企业应根据自己的实际情况去选择自己的技术路径。
它不一定具有通用性,但从一定程度讲,这个架构可能比BAT的架构更适应大多数企业的情况,毕竟,大多数企业,数据没到那个份上,也不可能完全自研,商业和开源的结合可能更好...
water
6年前 (2019-09-03) 2389℃ 0评论
1喜欢
作者:Bright Liao链接:https://www.zhihu.com/question/35425470/answer/62993113来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. 基于虚拟机的虚拟化和基于容器的...
water
6年前 (2019-08-27) 2396℃ 0评论
1喜欢
欧阳辰《Druid实时大数据分析》作者,”互联居”作者编辑推荐144 人赞同了该回答作者:欧阳辰链接:彪悍开源的分析数据库-ClickHouse – 互联居 – 知乎专栏来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商...
water
6年前 (2019-08-27) 3667℃ 0评论
2喜欢
本文将介绍机器学习领域经典的 FP-growth(Frequent Pattern Growth)模型,它是目前业界经典的频繁项集和关联规则挖掘的算法。相比于 Apriori 模型,FP-growth 模型只需要扫描数据库两次,极大得减少了数据读取次数并显著得提升了算法效率。您将...
water
6年前 (2019-05-14) 3531℃ 0评论
1喜欢
关联规则挖掘在电商、零售、大气物理、生物医学已经有了广泛的应用,本篇文章将介绍一些基本知识和Aprori算法。
啤酒与尿布的故事已经成为了关联规则挖掘的经典案例,还有人专门出了一本书《啤酒与尿布》,虽然说这个故事是哈弗商学院杜撰出来的,但确实能很好的解释关联规则挖掘的原理。我们这...
water
6年前 (2019-05-14) 2911℃ 0评论
0喜欢
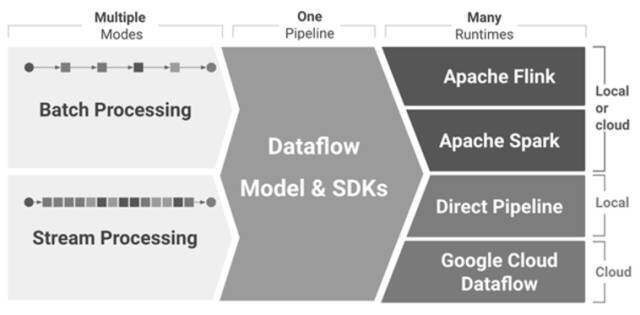
前言:大数据 2.0 时代不期而至
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。早期的处理模型 (Map/Reduce) 早已经力不从心,而且也很难应用到处理流程长且复杂的数据流水线上。另外,近年来涌现出诸多大数据应用...
water
6年前 (2019-04-22) 2665℃ 0评论
0喜欢
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; //&nb...
water
6年前 (2019-04-02) 3388℃ 0评论
0喜欢
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"。
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Re...
water
6年前 (2019-03-28) 3131℃ 0评论
2喜欢
很多人都知道大数据很火,就业很好,薪资很高,想往大数据方向发展。但该学哪些技术,学习路线是什么样的呢?用不用参加大数据培训呢?如果自己很迷茫,为了这些原因想往大数据方向发展,也可以,那么大讲台老师就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?是计算机专业,对操作系...
water
6年前 (2019-03-27) 2197℃ 0评论
0喜欢
目前啊,都知道,大数据集群管理方式分为手工方式(Apache hadoop)和工具方式(Ambari + hdp 和Cloudera Manger + CDH)。
手工部署呢,需配置太多参数,但是,好理解其原理,建议初学这样做,能学到很多。该方式啊,均得由用户执行,细节太多,切当...
water
6年前 (2019-03-12) 4736℃ 0评论
1喜欢
MapReduce按照任务大小和设置的不同,提供了两种任务模式:
老一些的版本还有一个JobTracker的实现类,即:classic。用于和MapReduce1.X兼容用的,高一些的版本已经没有这个实现类了。
一,本地模式(LocalJobRunner实现)
mapreduce...
water
6年前 (2019-03-07) 2445℃ 0评论
0喜欢
Kafka 0.9+增加了一个新的特性Kafka Connect,可以更方便的创建和管理数据流管道。它为Kafka和其它系统创建规模可扩展的、可信赖的流数据提供了一个简单的模型,通过connectors可以将大数据从其它系统导入到Kafka中,也可以从Kafka中导出到其它系统。...
water
7年前 (2018-09-06) 3449℃ 0评论
0喜欢
概述
谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生。但我们往往对它们的理解只是提留在字面上,并没有对它们进行深入的思考,下面不妨跟我一块看下它们究竟有什么异同。
解决问题的层面不一样
&nbs...
water
7年前 (2018-05-16) 2269℃ 0评论
0喜欢
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Hadoop、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。Parquet最初是由Twitter和Clo...
water
7年前 (2018-05-09) 3792℃ 0评论
0喜欢
前言
Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impala和Apache Spark等当前流行的大数据查询和分析工具结合紧密。本文将为...
water
7年前 (2018-05-09) 2935℃ 0评论
0喜欢