HDFS文件系统
一、HDFS设计
HDFS为hadoop的核心组件,为hadoop底层的文件存储系统。它通常运行在商用硬件集群上,用来存储超大文件、大规模文件。
1、超大文件
&q...
water
7年前 (2018-04-28) 2513℃ 0评论
0喜欢
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map...
water
7年前 (2018-03-06) 2838℃ 0评论
0喜欢
需要的安装包:
CDH-5.13.1-1.cdh5.13.1.p0.2-el7.parcel
CDH-5.13.1-1.cdh5.13.1.p0.2-el7.parcel.sha1
&...
water
7年前 (2018-02-11) 2565℃ 0评论
0喜欢
storm、spark streaming、flink都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂程度。
Apache Storm
在Storm中,先...
water
7年前 (2017-12-12) 3493℃ 0评论
0喜欢
1. Apache Kylin 是什么?
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
由eBay开源的一...
water
8年前 (2017-08-04) 2959℃ 0评论
0喜欢
取代Hadoop成为最活跃的开源大数据项目。但是,在选择大数据框架时,企业不能因此就厚此薄彼。近日,著名大数据专家Bernard Marr在一篇文章中分析了Spark和Hadoop的异同。
Hadoop和Spark均是大数据框架,都提供了一些执行常见大数据任务的工具。但确切地说,...
water
9年前 (2015-12-01) 3050℃ 0评论
0喜欢
大数据(Big Data)
大数据,官方定义是指那些数据量特别大、数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理。大数据的主要特点为数据量大(Volume),数据类别复杂(Variety),数据处理速度快(Velocity)和数据真实性高(Verac...
water
10年前 (2015-07-28) 3415℃ 0评论
0喜欢
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来。为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选择合适的技术,了解大数据各种技术之间的关系,选择合适的语言。
我们可以带着下面...
water
10年前 (2015-07-28) 3482℃ 0评论
0喜欢
云计算和Hadoop中网络是讨论得相对比较少的领域。本文原文由Dell企业技术专家Brad Hedlund撰写,他曾在思科工作多年,专长是数据中心、云网络等。文章素材基于作者自己的研究、实验和Cloudera的培训资料。
本文将着重于讨论Hadoop集群的体系结构和方法,及它如何...
water
10年前 (2015-03-23) 2744℃ 0评论
0喜欢
Hadoop已经成为大数据的代名词。短短几年间,Hadoop从一种边缘技术成为事实上的标准。而另一方面,MapReduce在谷歌已不再显赫。当企业瞩目MapReduce的时候,谷歌好像早已进入到了下一个时代。
Hadoop技术已经无处不在。不管是好是坏,Hadoop已经成...
water
10年前 (2015-03-23) 2976℃ 0评论
0喜欢
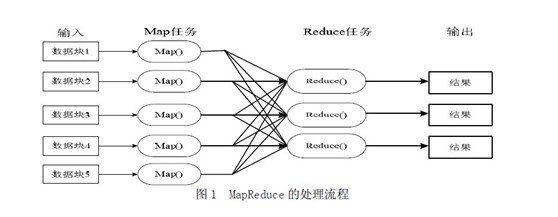
前言
几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,觉得它们很是神秘,而神秘的东西常能勾起我的兴趣,
在看过介绍它们的文章或论文之后,觉得Hadoop是一项富有趣味和挑战性的技术,且它还牵扯到...
water
10年前 (2015-03-23) 2958℃ 0评论
0喜欢