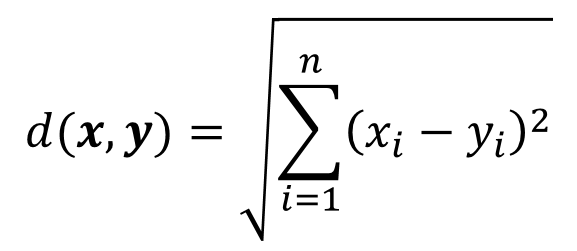计算化学中有时会要求我们计算两个向量的相似度,如做聚类分析时需要计算两个向量的距离,用分子指纹来判断两个化合物的相似程度,用夹角余弦判断两个描述符的相似程度等。计算向量间相似度的方法有很多种,本文将简单介绍一些常用的方法。这些方法相关的代码已经提交到github仓库
h...
water
3年前 (2022-06-13) 2481℃ 0评论
0喜欢
链接:https://zhuanlan.zhihu.com/p/364923722
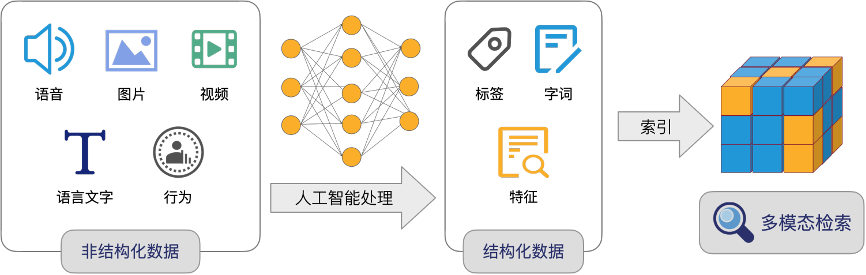
引用文章[7]的开篇,来表示什么是: 向量化搜索人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些...
water
3年前 (2022-06-09) 4683℃ 0评论
0喜欢
知乎上链接:https://zhuanlan.zhihu.com/p/115690499
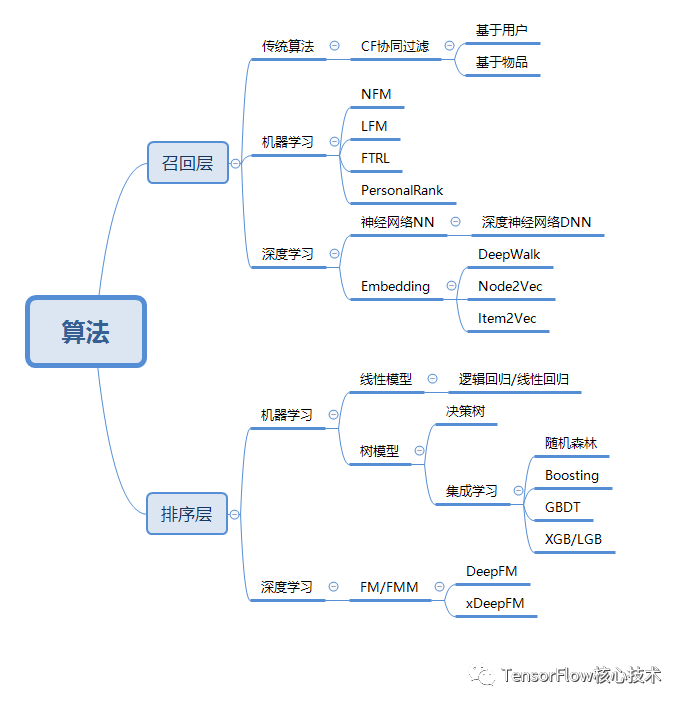
目前工业界常用的召回排序模型主要有:
召回模型
(1)基于内容的召回CB(Content–Base)
使用item之间的相似性来推荐与用户喜欢的item...
water
3年前 (2021-11-09) 3243℃ 0评论
0喜欢
1. 引言
小麦同窗是个吃货+技术宅,平日里就喜欢拿着手机地图点点按按来查询一些好玩的东西。某一天到北海公园游玩,肚肚饿了,因而乎打开手机地图,搜索北海公园附近的餐馆,并选了其中一家用餐。饱暖思yin欲的麦叔饭后思考地图后台如何根据本身所在位置查询来查询附近餐馆的呢?苦思...
water
4年前 (2020-11-24) 2490℃ 0评论
0喜欢
提到缓存,有两点是必须要考虑的:(1)缓存数据和目标数据的一致性问题。(2)缓存的过期策略(机制)。
其中,缓存的过期策略涉及淘汰算法。常用的淘汰算法有下面几种:(1)FIFO:First In First Out,先进先出(2)LRU:Least Recently U...
water
5年前 (2020-07-01) 3119℃ 0评论
1喜欢
电商环境下的个性化推荐,主要包含三大维度的模块,针对用户的候选召回(Match),候选商品的精排(Rank),以及线上的策略调控(Re-rank)。而Match(召回)和Rank(排序)是推荐流程非常关键的两步。
一、Match
Match即有效和丰富的召回...
water
5年前 (2020-02-04) 5396℃ 0评论
4喜欢
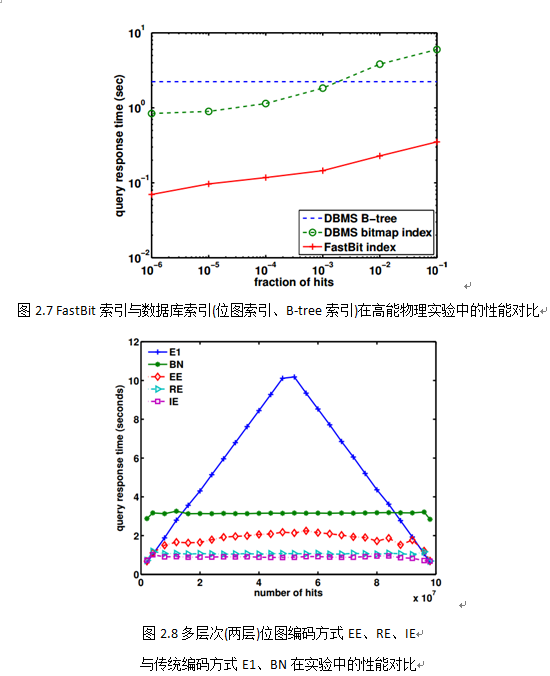
本节所介绍的FastBit是位图索引技术的集大成者,是一系列高级位图索引技术的集合,该项目最初设计目标是为美国国家高能物理实验提供支撑。
在FastBit中,两个核心创新点分别是:
字对齐混合压缩编码WAH,根据官方实验数据显示,其在高能物理实验中的索引性能是传统数据库...
water
5年前 (2019-12-11) 3159℃ 0评论
1喜欢
0x00 前言
位图索引被广泛用于数据库和搜索引擎中,通过利用位级并行,它们可以显著加快查询速度。但是,位图索引会占用大量的内存,因此我们会更喜欢压缩位图索引。 Roaring Bitmaps 就是一种十分优秀的压缩位图索引,后文统称 RBM。
压缩位图索引有很多种...
water
5年前 (2019-12-11) 2460℃ 0评论
1喜欢
在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID、退款ID等。那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十分重要的。下面我们一一来列举一下,不一定全部适合,这些解决方案仅供你参考,或许对你有...
water
6年前 (2019-07-26) 2279℃ 0评论
0喜欢
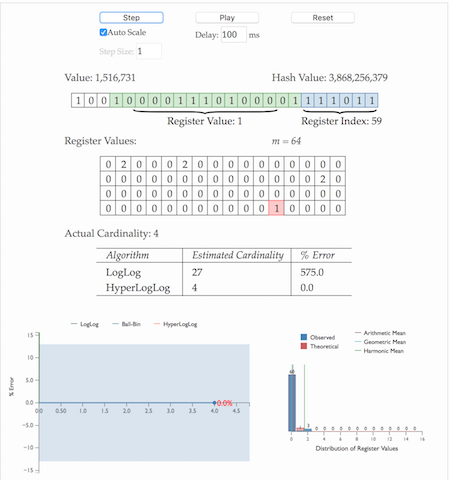
基数计数基本概念
基数计数(cardinality counting)通常用来统计一个集合中不重复的元素个数,例如统计某个网站的UV,或者用户搜索网站的关键词数量。数据分析、网络监控及数据库优化等领域都会涉及到基数计数的需求。 要实现基数计数,最简单的做法是记录集合中所有不重复的...
water
6年前 (2019-07-05) 3559℃ 0评论
0喜欢
状态机
状态机,表示若干个状态,以及在这些状态之间的转义和动作的模型。1 状态机是一个离散数学模型。给定一个输入集合,根据对输入的接受次序来决定一个输出集合。
有限状态机
无限状态机
一般认为无限状态机很好,因为这表示计算能力更强,但是有限状态理论和模型在...
water
6年前 (2019-05-16) 3975℃ 0评论
1喜欢
数据结构中的堆栈
堆结构和栈结构
堆 结构是数据结构中的一种,比如数据结构还有平衡二叉树、红黑树等
堆也被称为优先队列。队列中允许的操作是先进先出(FIFO),在队尾插入元素,在队头取出元素。而堆也是一样,在堆底插入元素,在堆顶取出元素 ;
内存中的堆栈
堆内...
water
6年前 (2019-05-10) 2472℃ 0评论
0喜欢
hdfs dfs -getmerge /data/search/gome/suggestdata/part-* /tmp/part-00000
hdfs dfs -moveFromLocal /tmp/part-00000 /data/search/gome/suggestd...
water
6年前 (2019-04-24) 6620℃ 0评论
3喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所...
water
6年前 (2019-04-22) 3859℃ 0评论
1喜欢
1 概念 归一化:1)把数据变成(0,1)或者(-1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。2)把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经...
water
6年前 (2019-02-27) 3928℃ 0评论
1喜欢
还在读书,也在实验室帮忙做了些东西,自己也搭过几个网站。在周围人看来似乎好像我很厉害,做了那么多东西,但是我发现这些东西虽然是我做的,但是实际上我手把手自己写的代码却并没有多少,很多都是用开源的东西,我写的代码无非是把别人的东西整合下,类似于胶水一样的工作。我之前所认为的编程是全...
water
6年前 (2019-01-28) 3612℃ 0评论
0喜欢
选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。 多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮...
water
6年前 (2019-01-15) 2134℃ 0评论
1喜欢
1.跳跃表
2.FST+FSM
Finite StateTransducers 简称 FST,通常中文译作有穷状态转换器或者有限状态传感器,我更偏向于后者,因为后者更加贴近原意。FST目前在语音识别和自然语言搜索、处理等方向被广泛应用。FST的功能更类似于字典,Lucene4.0...
water
6年前 (2019-01-14) 2839℃ 0评论
0喜欢
1 lucene字典
使用lucene进行查询不可避免都会使用到其提供的字典功能,即根据给定的term找到该term所对应的倒排文档id列表等信息。实际上lucene索引文件后缀名为tim和tip的文件实现的就是lucene的字典功能。
...
water
6年前 (2018-12-18) 2305℃ 0评论
0喜欢
NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广。命名实体通常指的是文本中具有特别意义或者指代性非常强的实体,通常包括人名、地名、机构名、时间、专有名词等。NER系统就是从非结构化的文本中抽取...
water
7年前 (2018-09-10) 24967℃ 0评论
26喜欢