数据结构中的堆栈
堆结构和栈结构
堆 结构是数据结构中的一种,比如数据结构还有平衡二叉树、红黑树等
堆也被称为优先队列。队列中允许的操作是先进先出(FIFO),在队尾插入元素,在队头取出元素。而堆也是一样,在堆底插入元素,在堆顶取出元素 ;
内存中的堆栈
堆内...
water
6年前 (2019-05-10) 2468℃ 0评论
0喜欢
hdfs dfs -getmerge /data/search/gome/suggestdata/part-* /tmp/part-00000
hdfs dfs -moveFromLocal /tmp/part-00000 /data/search/gome/suggestd...
water
6年前 (2019-04-24) 6614℃ 0评论
3喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所...
water
6年前 (2019-04-22) 3851℃ 0评论
1喜欢
前言:大数据 2.0 时代不期而至
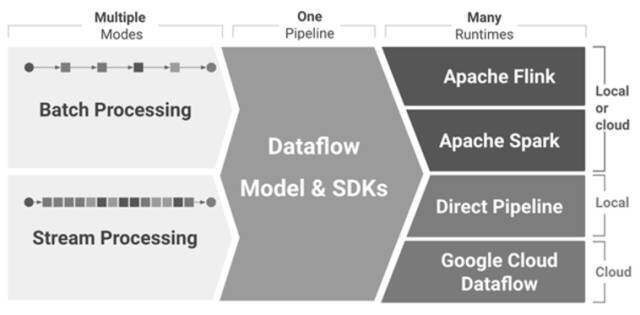
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。早期的处理模型 (Map/Reduce) 早已经力不从心,而且也很难应用到处理流程长且复杂的数据流水线上。另外,近年来涌现出诸多大数据应用...
water
6年前 (2019-04-22) 2659℃ 0评论
0喜欢
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; //&nb...
water
6年前 (2019-04-02) 3381℃ 0评论
0喜欢
本文简单介绍了持续集成的概念并着重介绍了如何基于 Gitlab CI 快速构建持续集成环境,主要介绍了 Gitlab CI 的基本功能和入门操作流程。
本文提到的 Gitlab 版本为 8.x ,新版的 Gitlab 界面可能会有所不同
什么是持续集成?
image.png...
water
6年前 (2019-03-29) 2793℃ 0评论
0喜欢
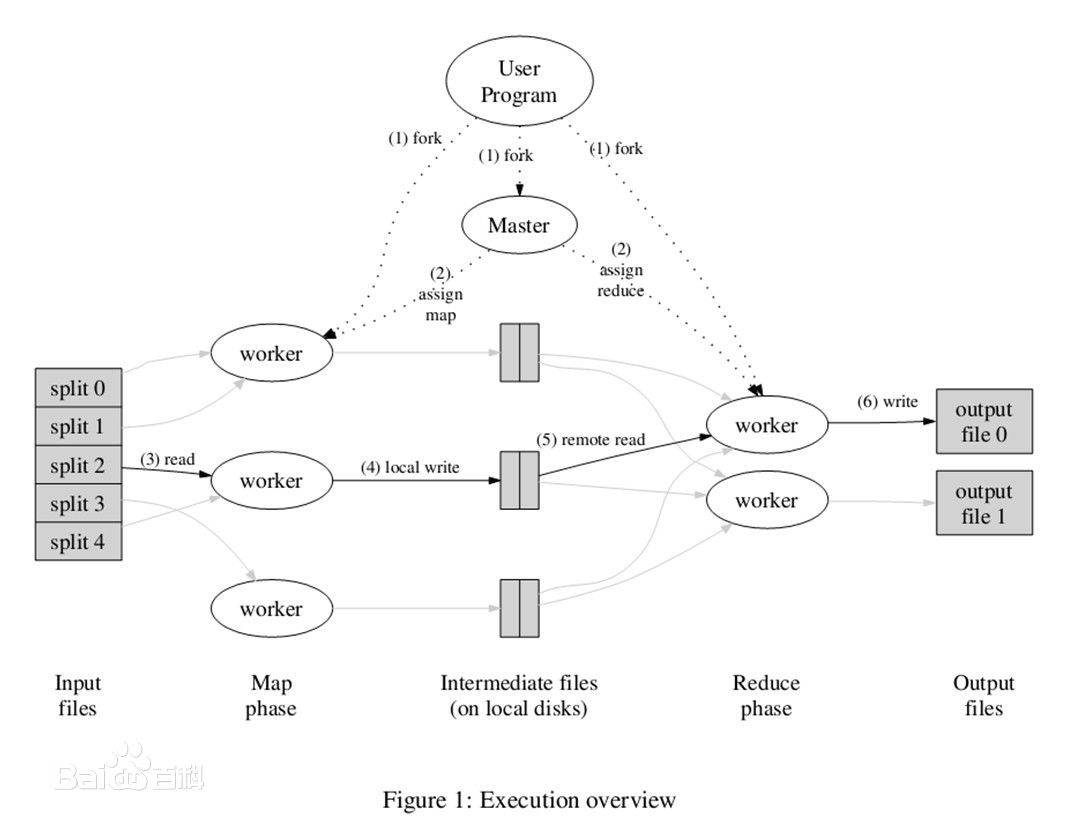
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"。
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Re...
water
6年前 (2019-03-28) 3124℃ 0评论
2喜欢
很多人都知道大数据很火,就业很好,薪资很高,想往大数据方向发展。但该学哪些技术,学习路线是什么样的呢?用不用参加大数据培训呢?如果自己很迷茫,为了这些原因想往大数据方向发展,也可以,那么大讲台老师就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?是计算机专业,对操作系...
water
6年前 (2019-03-27) 2193℃ 0评论
0喜欢
Azkaban概述
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
在介绍A...
water
6年前 (2019-03-13) 2935℃ 0评论
2喜欢
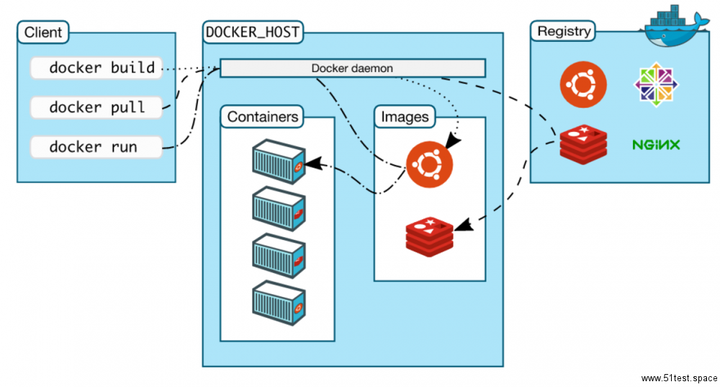
无数的文章、社交媒体在探讨Docker、Kubernetes、Mesos三者之间孰优孰劣。如果你听信了某些一知半解者的言论,你可能会认为这三个开源项目正在为争夺容器霸权而殊死战斗。同时,你也会相信,在这三者间的选择无异于对其所奉宗教的信仰,而且真正的信徒敢于大胆和异教徒作斗争,...
water
6年前 (2019-03-13) 2626℃ 0评论
1喜欢
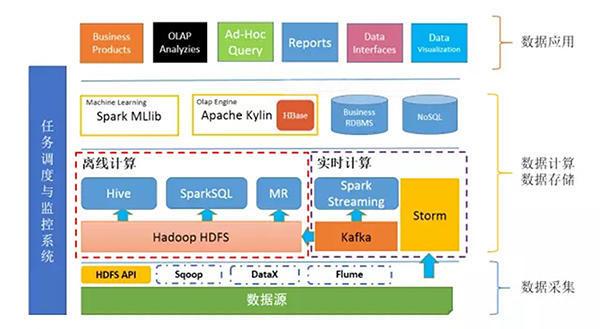
目前啊,都知道,大数据集群管理方式分为手工方式(Apache hadoop)和工具方式(Ambari + hdp 和Cloudera Manger + CDH)。
手工部署呢,需配置太多参数,但是,好理解其原理,建议初学这样做,能学到很多。该方式啊,均得由用户执行,细节太多,切当...
water
6年前 (2019-03-12) 4729℃ 0评论
1喜欢
MapReduce按照任务大小和设置的不同,提供了两种任务模式:
老一些的版本还有一个JobTracker的实现类,即:classic。用于和MapReduce1.X兼容用的,高一些的版本已经没有这个实现类了。
一,本地模式(LocalJobRunner实现)
mapreduce...
water
6年前 (2019-03-07) 2443℃ 0评论
0喜欢
、 设计规约1. 【强制】 存储方案和底层数据结构的设计获得评审一致通过,并沉淀成为文档。说明: 有缺陷的底层数据结构容易导致系统风险上升,可扩展性下降,重构成本也会因历史数据迁移和系统平滑过渡而陡然增加,所以,存储方案和数据结构需要认真地进行设计和评审,生产环境提交执行后,需要...
water
6年前 (2019-02-28) 2061℃ 0评论
0喜欢
阅读开源代码时可能经常遇到TODO、FIXME、XXX的单词,通常这些都是有其特殊含义的。
中文版的说明
TODO: + 说明:如果代码中有该标识,说明在标识处有功能代码待编写,待实现的功能在说明中会简略说明。
FIXME: + 说明:如果代码中有该标识,说明标识处代码需...
water
6年前 (2019-02-27) 2831℃ 0评论
0喜欢
1 概念 归一化:1)把数据变成(0,1)或者(-1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。2)把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经...
water
6年前 (2019-02-27) 3923℃ 0评论
1喜欢
还在读书,也在实验室帮忙做了些东西,自己也搭过几个网站。在周围人看来似乎好像我很厉害,做了那么多东西,但是我发现这些东西虽然是我做的,但是实际上我手把手自己写的代码却并没有多少,很多都是用开源的东西,我写的代码无非是把别人的东西整合下,类似于胶水一样的工作。我之前所认为的编程是全...
water
6年前 (2019-01-28) 3607℃ 0评论
0喜欢
微服务框架
服务注册与发现(Eureka) 客户端负载均衡(ribbon) 服务传输协议(rest,thrift) 服务熔断降级(...
water
6年前 (2019-01-22) 2201℃ 0评论
0喜欢
选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。 多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮...
water
6年前 (2019-01-15) 2131℃ 0评论
1喜欢
1.跳跃表
2.FST+FSM
Finite StateTransducers 简称 FST,通常中文译作有穷状态转换器或者有限状态传感器,我更偏向于后者,因为后者更加贴近原意。FST目前在语音识别和自然语言搜索、处理等方向被广泛应用。FST的功能更类似于字典,Lucene4.0...
water
6年前 (2019-01-14) 2831℃ 0评论
0喜欢
1 lucene字典
使用lucene进行查询不可避免都会使用到其提供的字典功能,即根据给定的term找到该term所对应的倒排文档id列表等信息。实际上lucene索引文件后缀名为tim和tip的文件实现的就是lucene的字典功能。
...
water
6年前 (2018-12-18) 2302℃ 0评论
0喜欢